

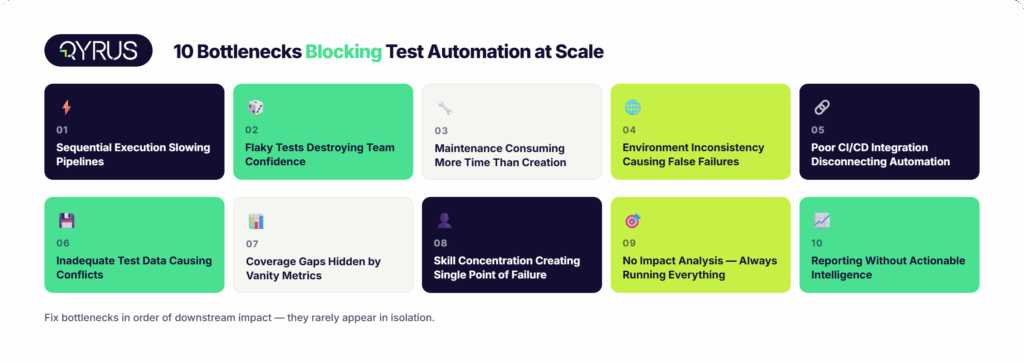
10 Bottlenecks That Block Scaling Test Automation
 Varun RS
Varun RS

Most test automation programs start strong. A few hundred tests, fast feedback, and streamlined CI pipelines. Eventually, the landscape shifts. The suite grows, the team grows, the product grows, and suddenly every merge takes 90 minutes to validate, engineers spend more time fixing broken tests than writing new ones, and QA has quietly become the bottleneck it was always meant to eliminate.

This is not a tooling problem. It is an architecture, process, and prioritization problem. And it is extremely common.
This post maps out the 10 most common bottlenecks that block teams from scaling test automation platforms effectively — with the symptoms to recognize them early, the root causes beneath the surface, and practical fixes QA leaders, test automation leads, and DevOps engineers can apply now.
Bottleneck 1: Sequential Test Execution Stifling Pipeline Velocity
Symptom
Your full regression suite takes 60, 90, or 120+ minutes to complete. Developers stop waiting for results and merge anyway.
Root Cause
Tests run one after another in a single thread. This worked fine at 50 tests. It does not work at 500 or 5,000. Sequential execution is not a deliberate choice at this point. Instead, it represents architectural debt from the suite’s early stages.
When CI feedback takes longer than a coffee break, engineers decouple from test results mentally. They start merging on gut feel, which defeats the entire purpose of automation.
Fix
Implement parallel test execution. Distribute tests across multiple agents, containers, or cloud nodes so that independent tests run simultaneously. A test suite that runs sequentially in 45 minutes can complete in under 8 minutes with proper parallelization. This represents an 82% reduction in build time.
Start by identifying tests that share no state or data dependencies and split those into parallel streams. Add test sharding and dynamic load balancing as the suite matures. For teams running cross-browser or cross-device validation, a cloud-based browser and device farm eliminates queue bottlenecks without maintaining physical hardware.
Bottleneck 2: Flaky Tests Destroying Team Confidence
Symptom
Tests pass locally but fail in CI. The same test fails on Monday and passes on Tuesday with no code changes. Developers add retry flags and move on.
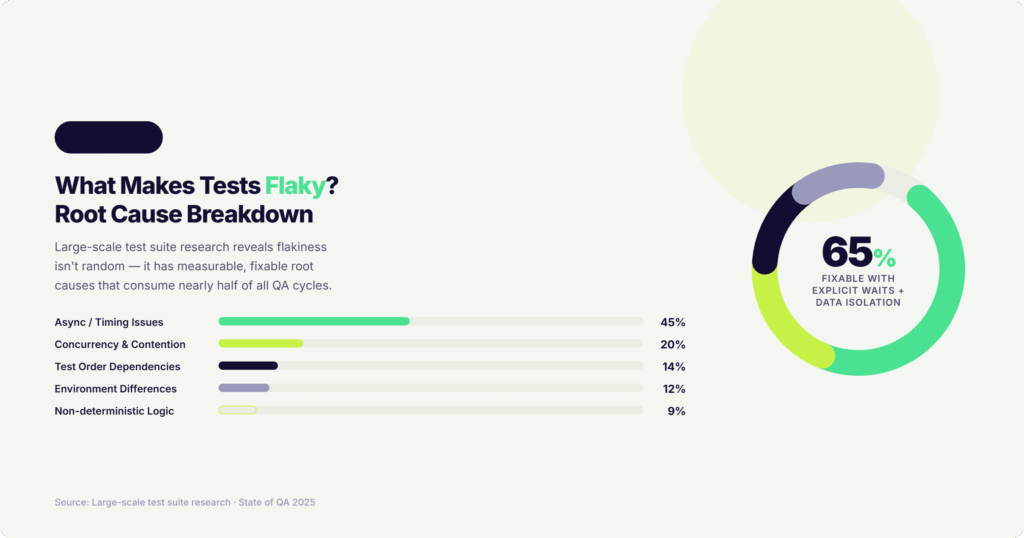
Root Cause
Research on large-scale test suites consistently shows that async wait and timing issues account for roughly 45% of flaky tests. Concurrency and resource contention cause 20% more. The remainder splits between test order dependencies, environment differences, and non-deterministic logic.
Retrying a failing test is the instinctive response — but retries inflate CI duration and, more damagingly, train teams to normalize failure. Eventually developers stop acting on red builds because they cannot distinguish noise from signals. The safety net becomes wallpaper.
Fix
Treat flakiness as a first-class engineering concern, not a QA nuisance. Instrument your CI pipeline to detect and quarantine flaky tests automatically. Replace hard-coded sleeps with explicit waits. Isolate test data so runs do not interfere with each other.
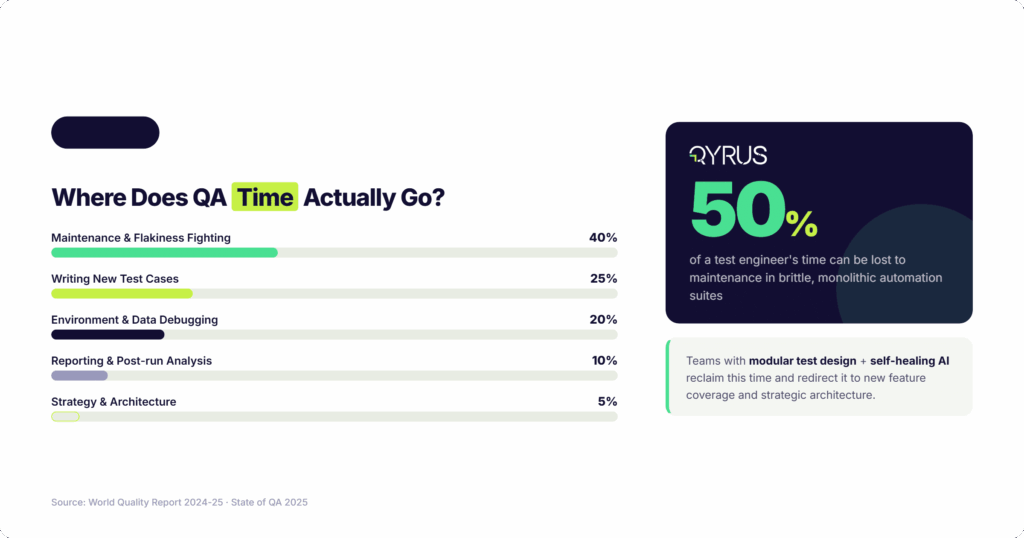
Stat: Test maintenance, including fighting flakiness, consumes roughly 40% of QA team time. (State of QA 2025)
Self-healing test capabilities, where AI automatically identifies updated locators when UI elements shift, directly address the most common root cause of brittleness in web and mobile automation.
Bottleneck 3: Test Suite Maintenance Consuming More Time Than Test Creation
Symptom
The sprint backlog is dominated by ‘fix broken test’ tickets. New feature coverage is falling behind because automation engineers are busy repairing old scripts.
Root Cause
Automation suites function as dynamic ecosystems. Applications change constantly — new UI components, refactored flows, updated APIs. Every change is a potential break. Without modular architecture, a single UI update can cascade into dozens of failing tests that each need individual repair. Up to 50% of a test engineer’s time can be consumed by maintenance in organizations running brittle, monolithic, script-based automation.
Fix
Modular test design is the highest-impact structural change a team can make. Encapsulate reusable flows — authentication, checkout, navigation — into shared components. When a flow changes, update the component once and all tests using it inherit the fix automatically.
Pair this with a regular test audit cadence. Retire tests that cover functionality no longer in production. Flag tests with a consistent failure rate above a set threshold for triage. A lean, reliable suite beats a sprawling, brittle one at any scale.
Bottleneck 4: Test Environment Inconsistency Causing False Failures
Symptom
Tests pass in staging, fail in QA, and behave unpredictably in CI. Environment differences account for a large share of investigation time that yields no actual bug.
Root Cause
Configuration drift. Development, staging, QA, and production environments diverge over time — different versions of dependencies, different database states, and different environment variables. Tests written against one configuration quietly break in another. The failure does not stem from the test logic but from an undefined environment state.
Fix
Adopt Infrastructure-as-Code (IaC) to define environments programmatically and keep them consistent across every pipeline stage. Use containerization (Docker) to replicate production configuration during testing. Define environment-specific variables in your test platform rather than hardcoding them into scripts, so the same test can execute across multiple environments without modification.
Bottleneck 5: Poor CI/CD Integration Leaving Automation Disconnected from Delivery
Symptom
Tests are triggered manually or on a schedule, rather than on every code push. Feedback arrives hours after a change, not minutes. Developers have already moved on by the time results land.
Root Cause
Test automation and CI/CD pipelines exist in separate silos. The tools are not wired together — either integration was never built, or it was built poorly, with no intelligent gate logic, no notification routing, and no pass/fail criteria tied to deployment decisions.
Fix
Native CI/CD integration is non-negotiable for scaling test automation platforms. Connect your test suite directly to your pipeline so every code commit triggers the appropriate test subset automatically — unit tests on every push, integration tests on every PR, full regression on merge to main. Build quality gates that block promotion based on test outcomes.
Stat: The DORA State of DevOps Report 2024 identifies test parallelization and CI/CD integration as the top techniques separating elite engineering teams from the rest, with elite teams maintaining median build times under 10 minutes.
Bottleneck 6: Inadequate Test Data Management Causing Hard Dependencies and Conflicts
Symptom
Tests fail because required test data does not exist, is stale, or was consumed by a previous run. Setting up data for a new scenario takes days. Parallel runs corrupt each other’s data.
Root Cause
Test data is treated as an afterthought rather than a managed resource. Teams either copy production data (fragile and non-compliant) or rely on manually created datasets that go stale as the application changes. At scale, a shared data pool becomes a contention point — parallel test runs race to read and modify the same records, producing unpredictable results.
Stats: 45% of respondents have 3–10 copies of each production dataset in non-production environments. (2025 State of Data Compliance and Security Report) | Teams with mature TDM practices release 3.2x faster than those without. (World Quality Report 2025)
Fix
Invest in parameterized, data-driven test design where each test scenario pulls from its own isolated dataset rather than a shared pool. Use synthetic data generation to create realistic, compliant datasets on demand — no production data copies required. Build data provisioning into the CI pipeline so the right data is ready before tests execute.
Bottleneck 7: Coverage Gaps Hidden by Vanity Metrics
Symptom
Automation coverage is reported at 80%+, but production defects keep slipping through. Post-mortems reveal the tested paths were not the ones that failed.
Root Cause
Coverage metrics measure which lines of code or test cases have been automated — not which business-critical flows have been validated end-to-end. Teams optimize for the metric rather than the outcome. Common side effects: over-automation of low-risk UI interactions, under-automation of API layers and backend integrations, and zero coverage of edge cases that only emerge under real load.
Fix
Reframe coverage as business process coverage, not code coverage. Map your most critical user journeys — registration, checkout, onboarding, payment processing — and confirm each one has complete automated validation from the API layer through the UI. Run exploratory test tools alongside scripted automation to surface untested pathways that scripted tests cannot reach by design.
Risk-based test selection — prioritizing automation for flows that carry the highest business risk, change most frequently, or have the highest defect history — delivers far more value than maximizing a coverage percentage.
Bottleneck 8: Skill Concentration Creating a Testing Bottleneck of One
Symptom
Only one or two engineers on the team can write or maintain automation scripts. Every new test request joins a queue behind them. Manual testing fills the gap.
Root Cause
Traditional automation frameworks require programming expertise — knowledge of Selenium, specific language bindings, locator strategies, and framework architecture. This creates a single-guild dependency where non-technical team members cannot contribute to automation regardless of their functional knowledge.
Stat: Over 88% of companies report struggling to find, hire, and retain quality automation engineers. (Techstrong Research)
Fix
Low-code and no-code test automation directly addresses this bottleneck by making test creation accessible without coding expertise. When a business analyst can build a test from a user story description and a manual tester can record and validate a scenario without writing a single line of code, the creation bottleneck breaks.
AI-powered test generation goes further — taking a Jira ticket or a natural language use case description and producing 60–80 functional test scenarios automatically. This does not replace automation engineers; it reallocates their focus from test authoring to architecture, tooling, and strategy.
Bottleneck 9: No Impact Analysis Leading to Always-Run-Everything Cycles
Symptom
Every commit triggers the full test suite, regardless of what changed. A CSS fix to the footer runs the payment integration tests. Execution time grows proportionally with suite size.
Root Cause
There is no intelligence connecting code changes to test selection. The default is to run everything, always — which is safe in theory but inefficient at scale. As suites grow to thousands of tests, ‘run everything’ becomes a delivery tax paid on every merge.
Fix
Implement test impact analysis to identify which tests cover the code changed in a specific commit, and run only those instead of the full suite. Organize your suite into fast-feedback layers:
- Smoke pack (5–10 minutes) — runs on every push
- Sanity pack (15–20 minutes) — runs on every PR
- Full regression pack — runs on merge to main or on schedule
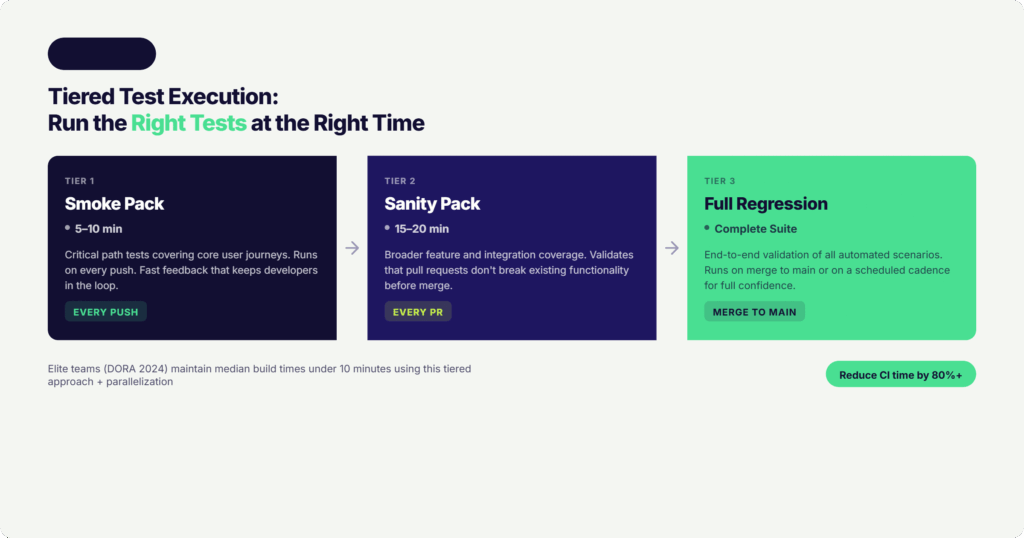
This tiered approach dramatically reduces CI time while maintaining appropriate coverage at each stage. AI-driven impact analysis — examining dependency graphs, historical failure data, and code change patterns — takes this further, delivering higher confidence with a smaller execution footprint.
Bottleneck 10: Reporting That Produces Data Without Actionable Intelligence
Symptom
Test results are available, but no one acts on them quickly. Root cause investigation requires diving through log files, comparing screenshots manually, and tracing failures across multiple tools. Post-run analysis takes longer than the run itself.
Root Cause
Reporting is treated as a log dump rather than a communication tool. Results are stored in one system, screenshots in another, CI logs in a third. There is no unified view that tells a developer or QA lead — at a glance — what failed, why it failed, and what the business impact is.
Fix
Consolidate reporting into a single, unified view that shows step-level execution details, failure screenshots, console logs, performance metrics, and issue-tracking integration in one place. Step-level granularity — showing exactly which action failed and what the actual versus expected result was — dramatically reduces investigation time compared to high-level pass/fail summaries.
Build notification routing into your test infrastructure. When a specific workflow fails, the right person should know within minutes, through Slack, email, Teams, or a Jira ticket, with enough context to act without hunting through dashboards.
Pulling It Together: A Self-Assessment Checklist for QA Leaders
The ten bottlenecks above rarely appear in isolation. Flaky tests compound slow execution. Poor test data management drives environment inconsistency. Skill concentration blocks the coverage expansion that impact analysis requires. Pick the bottleneck causing the most downstream damage and work forward from there.
- Regression runs taking more than 30 minutes? → Start with parallel execution (Bottleneck 1)
- Team spending more time on maintenance than creation? → Prioritize modular design and self-healing (Bottlenecks 2, 3)
- Environment failures masking real results? → Tackle IaC and configuration management (Bottleneck 4)
- CI results arriving too late to influence developer behavior? → Fix CI/CD integration first (Bottleneck 5)
- Tests failing because data is missing or conflicting? → Build a test data strategy (Bottleneck 6)
- Only one person able to create automation? → Invest in low-code tooling and AI test generation (Bottleneck 8)
How Modern Platforms Accelerate This Work
Fixing these bottlenecks is significantly harder with fragmented toolchains — one tool for web automation, another for API testing, a third for CI integration, a fourth for reporting. Every seam between tools is a maintenance burden and an integration risk.
Modern unified testing platforms are designed to address this architectural fragmentation. Qyrus, for example, brings web, mobile, API, and SAP testing onto a single platform with:
- Built-in parallel execution across a cloud browser and device farm
- Native CI/CD integrations (Jenkins, Azure DevOps, Bitrise, TeamCity, Concourse)
- Self-healing AI (Healer) that automatically repairs broken locators after UI changes
- AI-powered test generation (NOVA and TestGenerator+) that creates scenarios from Jira tickets or plain-English descriptions
- Parameterization and data-driven testing for isolated, reusable test data
- Granular step-level reporting with screenshots, console logs, and performance metrics — all without writing code
The practical effect: teams can address multiple bottlenecks simultaneously rather than purchasing and integrating point solutions for each one.
Final Thought
Scaling test automation platforms is not about running more tests. It is about running the right tests, reliably, fast enough to influence decisions, with low enough maintenance overhead that the suite stays trustworthy as the product grows.
Each of the ten bottlenecks above represents a point where automation effort exceeds automation value. Removing them — one by one, in order of impact — is how QA teams transform from a delivery gate into a delivery accelerator.
The teams that get this right don’t just ship faster. They ship with confidence.
Want to see how Qyrus helps QA and DevOps teams tackle these scalability challenges end-to-end? Book a demo today.

 July 2, 2026
July 2, 2026  13 min
13 min





