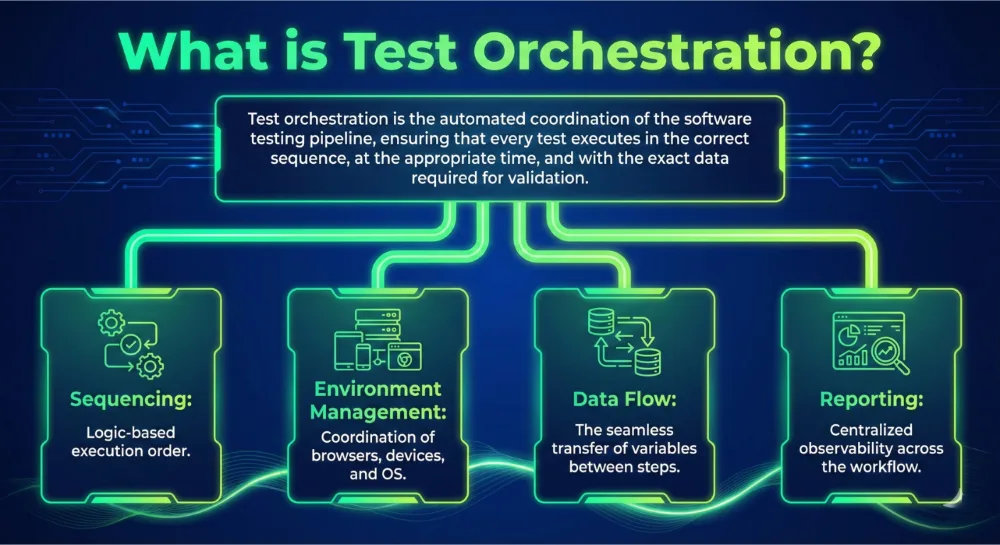
Shattering the Black Box with Total Visibility
Isolated scripts often create a “black box” where results are difficult to interpret. You might see a failure, but finding the root cause requires manual digging through logs. Automated test orchestration replaces this confusion with a transparent, visual pipeline. You see every step of the user journey as it happens. This clarity allows your team to pinpoint exactly where a process breaks, whether it occurs in an API call or a mobile UI element.
Hardening Production with Intelligent Quality Gates
Moving fast requires guardrails. Validated releases depend on “Quality Gates” that automatically block unstable code from moving forward. Using test orchestration tools, you set specific criteria for success at every stage of the pipeline. If a critical smoke test fails, the orchestrator halts the deployment immediately. This ensures only 100% verified features reach your users, maintaining your brand’s reputation for reliability.
The Economic Impact of Automated Test Orchestration
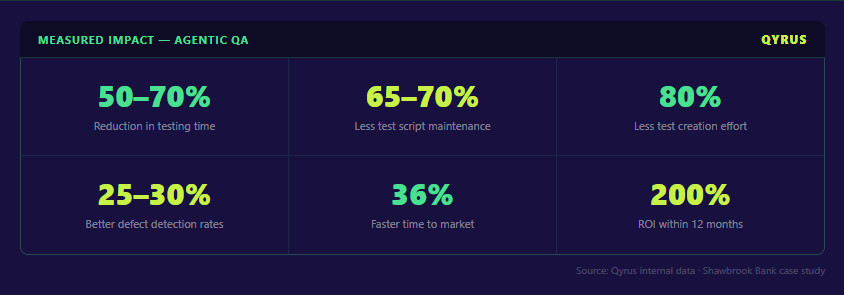
The financial argument for this shift remains undeniable. Research indicates that organizations adopting these strategies experience shorter test cycles compared to those using fragmented automation. Furthermore, these teams achieve better success rate in production releases. By streamlining the validation process, you reduce maintenance overhead by nearly 80%. This efficiency frees up your budget for innovation rather than constant troubleshooting.
Unifying Engineering through Workflow-Based Test Automation
Traditional testing often happens in a silo, separated from development and operations. Workflow-based test automation breaks down these barriers. It provides a shared “source of truth” that every department can access and understand. When developers, QA engineers, and DevOps professionals look at the same orchestration dashboard, they collaborate more effectively. This alignment accelerates the entire lifecycle. It ensures everyone works toward the same objective: delivering value to the customer.
What Test Orchestration Looks Like in Action
Test orchestration moves beyond the theory of “running tests” and enters the practice of managing business risks at scale. In a modern software environment, a single release often involves an API update, a change to the web checkout UI, and a new promotion in the mobile app. Standalone scripts struggle to bridge these gaps. However, with automated test orchestration, you build a unified flow that treats these separate components as one cohesive journey.
High-Level Workflow Examples
The Smoke Test: Rapid Validation
Teams use smoke tests to perform quick, automated checks of critical functionality. The goal remains simple: verify the application works at a basic level before committing further resources. A well-orchestrated smoke suite should validate critical paths in less than 15 minutes after a deployment. This rapid feedback loop allows you to detect obvious issues immediately, preventing the team from wasting time on a fundamentally broken build.
The Regression Suite: Enterprise-Scale Chaining
As applications grow, so does the risk of “breaking” existing features. A comprehensive regression suite often requires chaining 10 or more workflows to achieve full system validation. Using test orchestration tools, you can organize these workflows into a logical hierarchy. If the “User Authentication” workflow fails, the system automatically halts the “Payment Processing” and “Order History” flows. This prevents the “crushing weight of maintenance” often seen in legacy systems, where most test automation projects fail due to a lack of coordination.
The API-to-Web Journey: Cross-Platform Fluidity
Real users do not live in silos; neither should your tests. An API-to-Web journey mirrors a real-world scenario by creating a user via an API call and immediately verifying that account on the Web UI. This requires seamless data propagation, where the session token or user ID from the first node becomes the input for the next. This workflow-based test automation ensures that your back-end and front-end systems communicate perfectly.
Real-World Architectures: The CI/CD Connection
Effective test orchestration relies on deep integration with your existing DevOps stack. Since more than 80% developers now work in DevOps environments, your orchestration engine must respond instantly to CI/CD triggers.
Whether you use Jenkins, Azure DevOps, or GitLab, the architecture remains consistent. When a developer pushes code to a repository, the CI/CD tool sends a trigger to the orchestration platform. The engine then selects the appropriate environment—be it Staging, UAT, or Production—and begins the execution.
By embedding these checks directly into the pipeline, you create “Quality Gates” that block unstable code. This automated choreography ensures that your release cycle stays fast without sacrificing the reliability your customers expect.
Anatomy of an Orchestrated Test Workflow
Orchestration begins with sequencing. You organize tests into logical units such as authentication, onboarding, or checkout. Traditional methods run scripts one after another in a linear queue. However, modern test orchestration tools enable parallel execution logic, which can reduce execution time by up to 90%. Chaining tests ensures that a subsequent stage only begins after a prior stage succeeds. For example, if the authentication stage fails, the orchestrator halts checkout testing to save compute resources.
Data Management and State Persistence
Data management serves as the fuel for these workflows. Successful test orchestration requires sharing session data, tokens, and identifiers across different platforms. You must pass a customer ID from an account creation step to the purchase validation step without manual entry. Furthermore, environment persistence maintains the application state throughout the entire process. This ensures that database snapshots or session cookies remain valid as the test progresses from an API call to a mobile interface.
Resilience Through Failure Handling
Reliable workflows include robust failure handling to prevent brittle pipelines. If a test fails, you need a strategy beyond simple termination. Automated test orchestration allows you to define specific retry, abort, or skip logic. For instance, if a non-critical UI element fails, the system might skip that step to continue the broader validation. In contrast, a failure in the login stage should abort the entire flow to prevent false positives. Advanced platforms even use self-healing mechanisms to address UI changes, which can slash maintenance efforts by 81%.
Centralized Analytics and Observability
The final piece involves results and analytics. Centralized reporting dashboards aggregate logs, videos, and performance metrics from every tool in the testing suite. You track specific KPIs such as pass/fail trends and execution duration to measure the health of your workflow-based test automation. These insights transform raw outcomes into a clear picture of overall software quality. Qyrus provides this transparency through its Mind Maps, which offer a visual, hierarchical view of the entire test repository and its execution status.
How Test Orchestration Integrates with CI/CD & DevOps
Modern software delivery requires a seamless connection between code changes and validation. When you integrate test orchestration into your DevOps pipeline, you move beyond simple automation. Your CI/CD tools, such as Jenkins or Azure DevOps, no longer just trigger scripts; they manage a sophisticated choreography of validation steps.
Automated test orchestration introduces intelligent quality gates. These gates evaluate the health of a build in real-time. If a critical workflow fails, the orchestrator blocks the deployment immediately. This proactive approach prevents the accumulation of technical debt and protects the user experience.
Effective test orchestration tools also provide immediate observability. Instead of searching through logs, your team receives results directly in Slack or Jira. This rapid feedback loop allows development teams to fix bugs as soon as they appear. Workflow-based test automation ensures that every code commit undergoes a rigorous, multi-environment check before it ever touches a customer.
Selecting the Best Test Orchestration Tools & Platforms
Choosing from the available test orchestration tools requires an understanding of how different architectures impact your long-term maintenance. The market generally splits into three categories. First, built-in orchestration engines exist within larger testing platforms. These offer native integration but may limit your flexibility. Second, plugin tools attach to your existing CI/CD pipeline. While these provide modularity, they often lead to “tool sprawl,” where engineers spend more time managing integrations than writing tests. Finally, full platform orchestration stacks provide a unified environment for cross-platform validation.
Transitioning to a unified platform often reveals the inherent limitations of older, siloed testing models that lack cross-protocol support. (If your team currently relies on older frameworks, you should examine Why Traditional Component Testing Breaks at Scale to understand why a shift to orchestration is mandatory for enterprise growth.)
The debate between code-based orchestration and visual workflow builders also shapes your team’s productivity. Code-based frameworks provide deep customization for highly technical teams. However, they often recreate the “crushing weight of maintenance” that causes test automation projects to fail. In contrast, visual builders democratize the process. They allow manual testers and product owners to contribute to the quality strategy without learning complex syntax. This shift is vital because 35% of companies still struggle with manual testing as their primary bottleneck.
Orchestrating at Scale with Qyrus
Qyrus offers a next-generation approach to automated test orchestration through its dedicated TO module. This platform eliminates the obstacles that hinder team progress by providing a high-performance environment for complex test scenarios.
- Flow Master Hub: This is your command center. Use the advanced drag-and-drop interface to create and edit test flows visually. It handles intricate user journeys across Web, Mobile, API, and Desktop platforms in a single execution.
- The Vault: Scale requires organization. The Vault provides a hierarchical structure to categorize projects by environments like QA, UAT, and Production. Advanced nesting and filtering tools ensure your team never wastes time hunting for the correct files.
- SmartFlow Mapping: Rigid paths lead to fragile tests. This feature adapts to live conditions during execution. If a login fails or a transaction lacks a balance, the mapper reroutes the test automatically to handle the edge case.











![Featured_Image-LLM_evaluation[1]](https://www.qyrus.com/wp-content/uploads/2026/03/Featured_Image-LLM_evaluation1.webp)