Software quality engineering is entering a decisive new phase. For over a decade, AI in testing has been largely predictive, focused on classifying defects, detecting anomalies, and optimizing execution. While effective, these models operate within predefined boundaries.
This paradigm shifts fundamentally with generative AI.
This approach for testing refers to the use of large language models (LLMs) and generative systems to create test artifacts directly from natural language inputs such as user stories, acceptance criteria, design files, and even production telemetry. Instead of analyzing outputs, these systems generate test cases, scripts, and data from intent.
This shift is not incremental. It redefines how testing is designed, executed, and maintained.
By 2026, generative AI is transitioning from experimentation to operational necessity. Increasing application complexity, distributed architectures, and compressed release cycles are pushing QA teams toward systems that can scale test creation and adaptation autonomously. Organizations that adopt generative testing early are already seeing measurable gains in speed, coverage, and resilience.
The Current Market Landscape: Beyond the Hype
The rapid evolution of generative AI in testing is reflected in its market trajectory. The segment is expected to grow from approximately $48.9 million in 2024 to $351.4 million by 2034, according to Future Market Insights’ research on generative AI in software testing, signaling strong enterprise demand and sustained investment.
Additional industry signals reinforce this shift:
- Over 65% of organizations are already experimenting with AI in QA, based on Capgemini World Quality Report 2023–24.
- AI adoption in software engineering is expected to contribute up to $4.4 trillion annually to the global economy, according to McKinsey’s generative AI report.
- Poor software quality cost U.S. businesses over $2.41 trillion in 2022, according to the CISQ Cost of Poor Software Quality report.
- 80% of QA teams plan to increase investment in AI-driven testing, as highlighted in the World Quality Report.
Despite this growth, the market remains fragmented.
A critical distinction exists between:
General AI-Augmented Testing Tools
These tools incorporate AI for:
- Visual regression detection
- Flaky test identification
- Execution optimization
While valuable, they remain reactive and limited to specific phases of the testing lifecycle.
Generative AI-Native Testing Platforms
These platforms embed LLMs across the testing lifecycle to:
- Generate test scenarios from requirements
- Create executable scripts dynamically
- Produce synthetic datasets at scale
- Continuously evolve tests based on production signals
This category represents a structural shift toward agent-driven testing ecosystems, where intelligent systems orchestrate test design, execution, and maintenance end-to-end.
Enterprises are increasingly prioritizing these platforms to reduce test debt, accelerate delivery pipelines, and achieve continuous quality at scale.
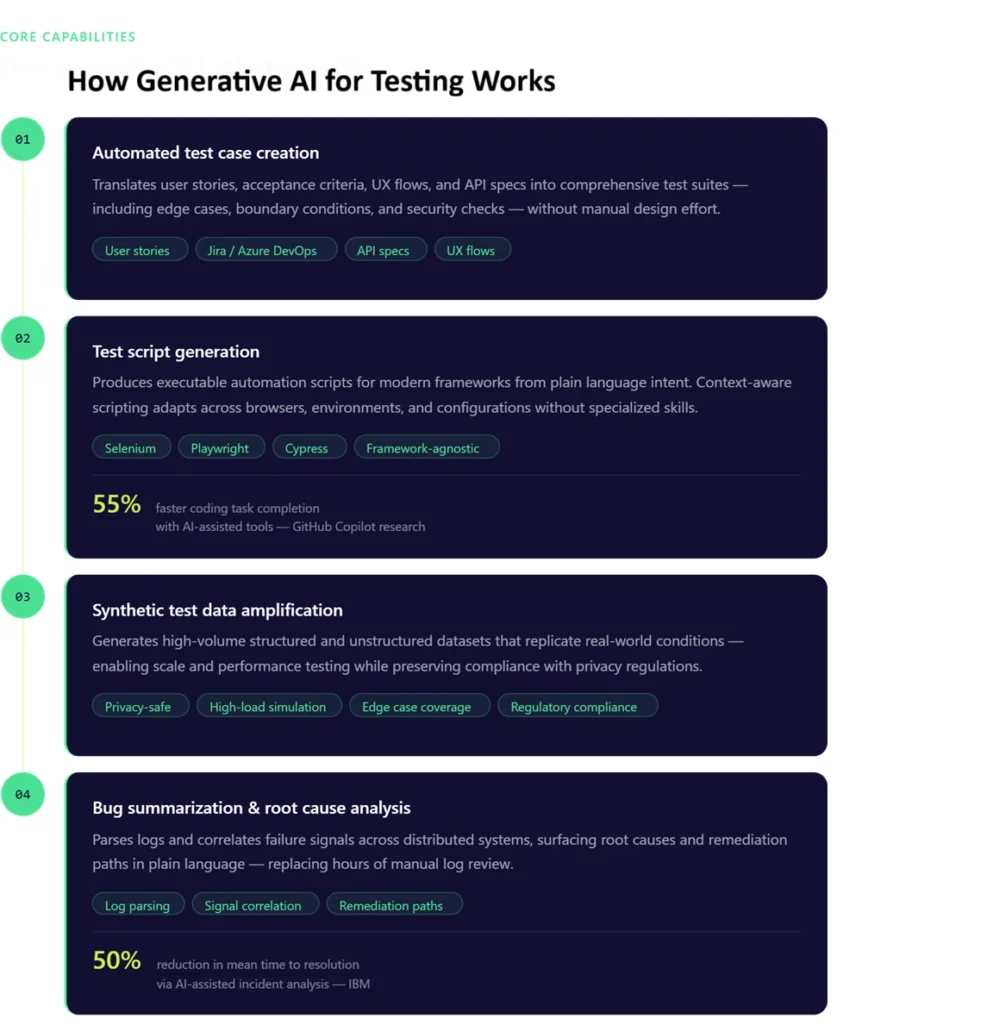
Core Pillars: How Generative AI for Testing Works
At its core, generative AI transforms testing through four foundational capabilities.
1. Automated Test Case Creation
Generative AI systems translate business intent into structured, executable test scenarios.
By analyzing inputs such as:
- User stories from Jira
- Acceptance criteria
- API specifications
- UX flows from design tools
LLMs generate comprehensive test suites that include:
- Functional scenarios
- Negative test paths
- Boundary conditions
- Security and validation checks
Example:
A requirement such as password reset functionality is expanded into dozens of scenarios, including token expiry validation, rate limiting, invalid credential handling, and concurrency edge cases.
This approach eliminates manual test design bottlenecks and significantly improves coverage, particularly for edge cases that are often missed in traditional workflows.
- Test Script Generation
Beyond scenario creation, generative AI produces executable automation scripts aligned with modern frameworks such as Qyrus, Selenium, Playwright, and Cypress.
Instead of manually writing scripts, teams can:
- Describe test intent in natural language
- Generate framework-specific code instantly
- Adapt scripts across browsers, environments, and configurations
Advanced implementations go further by generating context-aware scripts, where the model understands application structure, locators, and workflows. Developers using AI-assisted tools can complete coding tasks up to 55% faster, according to GitHub Copilot research.
This reduces dependency on specialized automation skills and accelerates time-to-automation, especially in large-scale enterprise environments.
- Data Amplification with Synthetic Test Data
Data limitations have historically constrained test coverage, particularly in regulated industries.
Generative AI addresses this through data amplification, creating high-volume synthetic datasets that replicate real-world conditions without exposing sensitive information.
Capabilities include:
- Generating structured and unstructured datasets
- Simulating rare and extreme edge cases
- Supporting high-load and performance testing scenarios
- Preserving statistical integrity of production data
By 2030, synthetic data is expected to dominate AI training datasets, according to Gartner’s research on synthetic data.
As a result, teams can test at scale while maintaining compliance with privacy and regulatory requirements.
- Bug Summarization and Root Cause Analysis
Modern systems generate vast volumes of logs, traces, and telemetry data. Identifying the root cause of failures in this data is time intensive.
Generative AI simplifies this process by:
- Parsing logs and execution data
- Correlating failure signals across systems
- Explaining issues in plain, contextual language
AI-assisted incident analysis can reduce resolution time by up to 50%, based on IBM research on AI in DevOps.
For example, instead of reviewing thousands of log lines, teams receive concise summaries such as:
- Root cause identification
- Impacted components
- Suggested remediation paths
The impact is a significant reduction in mean time to resolution and improves collaboration between QA, development, and DevOps teams.
Integrating Generative AI: From “Shift-Left” to “Monitor-Right”
Generative AI extends testing beyond traditional boundaries, creating a continuous quality loop.
Shift-Left: Proactive Test Generation
Testing begins at the earliest stages of development.
As soon as requirements or design artifacts are available, generative systems:
- Create initial test scenarios
- Identify gaps in requirements
- Generate validation criteria before code is written
Organizations adopting shift-left testing can detect up to 85% of defects earlier, according to IBM Shift-Left Testing insights.
This reduces downstream defects and ensures that quality is embedded from the outset.
Monitor-Right: Continuous Learning from Production
Generative AI also operates in production environments by:
- Analyzing real user behavior
- Detecting anomalies and failure patterns
- Generating new test cases based on observed issues
For example, if a specific user flow fails under high concurrency in production, the system can automatically generate test scenarios to replicate and prevent the issue in future releases.
The Result: Continuous Testing Intelligence
By connecting shift-left and monitor-right:
- Test cycles become shorter and more efficient
- Coverage evolves dynamically based on real-world usage
- Manual effort is reduced in high-risk and high-impact areas
This creates a self-improving testing ecosystem aligned with modern DevOps practices.

Solving the “Maintenance Hell” with Self Healing
Test maintenance remains one of the most significant sources of inefficiency in QA.
Traditional automation relies on brittle scripts with hard-coded selectors. Even minor UI changes can break test suites, creating a cycle of constant maintenance—commonly referred to as test debt.
Up to 30–40% of automation effort is spent on maintenance, according to Capgemini Quality Engineering research.
Generative AI addresses this through self-healing mechanisms.
Key capabilities include:
- Detecting UI and DOM changes automatically
- Updating locators and workflows dynamically
- Reconstructing test steps based on intent rather than static selectors
For example, instead of failing due to a changed XPath, the system identifies the semantic role of an element (such as a login button) and adapts accordingly.
This shift from selector-based automation to intent-based testing dramatically reduces flakiness and eliminates repetitive maintenance tasks.
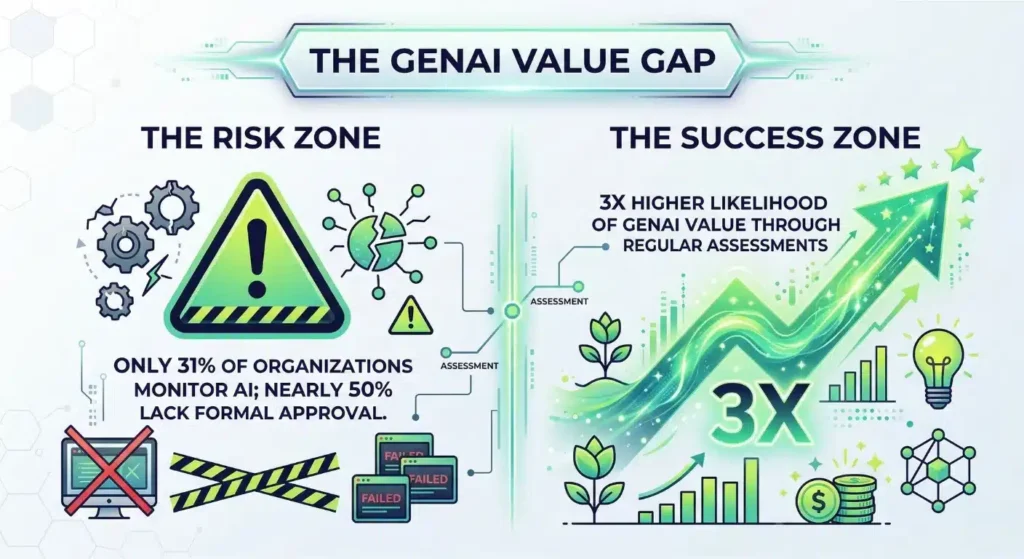
The Human-in-the-Loop: Ethics and Reliability
While generative AI enhances testing capabilities, human oversight remains critical for ensuring reliability and trust.
Adversarial Testing and Validation
Generative systems can be used to uncover vulnerabilities and unexpected behaviors. However, human reviewers are essential to:
- Validate ambiguous outputs
- Ensure alignment with business logic
- Confirm correctness in complex scenarios
Bias, Hallucinations, and Semantic Validation
LLMs can generate incorrect or misleading outputs if not properly constrained.
To mitigate this, organizations implement:
- Semantic validation layers to verify correctness
- Guardrails aligned with application logic
- Evaluation frameworks to continuously assess model performance
This ensures that generated tests remain grounded in actual system behavior rather than inferred assumptions.
Continuous Reporting and Feedback Loops
Effective reporting is essential for improving generative systems.
By analyzing:
- Test outcomes
- Failure patterns
- Model inaccuracies
Teams can refine models, improve accuracy, and reduce false positives over time.
The most effective implementations treat generative AI as a collaborative system, where human expertise guides and enhances machine-generated outputs.
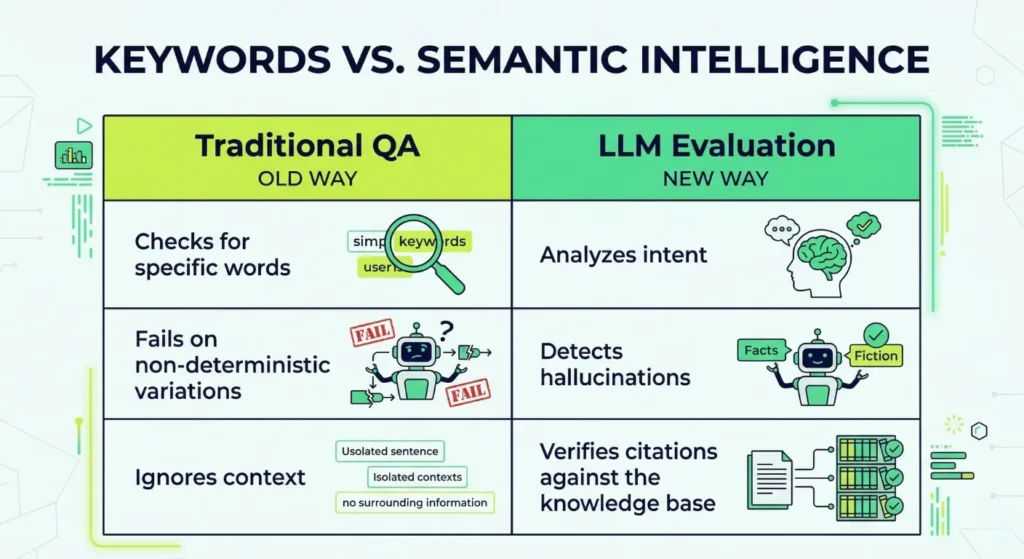
Comparative Analysis: Manual vs. Traditional Automation vs. GenAI
Criteria | Manual Testing | Traditional Automation | Generative AI Testing |
Test Creation Speed | Slow | Moderate | Near-instant |
Test Coverage | Limited | Moderate | Extensive (including edge cases) |
Maintenance Effort | Low | High (script-heavy) | Minimal (self-healing) |
Scalability | Low | Moderate | High |
Adaptability | Low | Moderate | Dynamic and context-aware |
Test Debt Impact | Minimal | High | Continuously reduced |
Time to Feedback | Slow | Moderate | Real-time or near real-time |
Generative AI not only accelerates testing but fundamentally improves coverage quality and system adaptability.
Top Generative AI Testing Tools to Watch
The 2026 landscape is defined by platforms that integrate generative AI across the testing lifecycle.
Qyrus
Qyrus integrates Generative AI, Large Language Models (LLMs), and Vision Language Models (VLMs) into its Qyrus AI Verse suite to drive a “shift-left” approach, allowing teams to test earlier and more efficiently in the software development lifecycle. The platform deploys these AI capabilities across several specialized tools to automate and enhance quality assurance:
Test Scenario and Script Generation
- Test Generator uses AI to automatically draft 60 to 80 functional test scenarios per use case by analyzing text inputs like user descriptions, JIRA tickets, Azure DevOps items, or Rally Work Items.
- TestGenerator+ leverages AI to analyze a team’s existing test scripts and automatically generate new scripts, saving time when expanding regression suites or validating new features.
- Underlying these capabilities are AI engines like Nova (which generates tests from text-based business requirements) and Vision Nova (which generates functional and visual accessibility tests by analyzing application screenshots or image URLs).
Bridging Design and Testing
- UXtract uses AI to analyze Figma designs and interactive prototypes, generating test scenarios, API structures, and test data before development even begins. It also performs automated visual accessibility checks to ensure designs comply with WCAG 2.1 standards.
API and Test Data Automation
- API Builder uses AI to rapidly generate fully functional APIs, Swagger JSON definitions, and mock URLs based on simple text descriptions (e.g., “Build APIs for a pet shop”).
- Echo (powered by Data Amplifier) automates data preparation by taking sample inputs and generating vast amounts of structured, formatted test data for parameterized testing and database stress testing.
Intelligent Test Execution and Exploration
- Qyrus TestPilot features specialized AI agents, such as WebCoPilot for generating and executing web application tests, and API Bot for analyzing APIs and building intelligent execution workflows from Swagger documents.
- Rover 2.0 uses a large-language-model “brain” to conduct autonomous exploratory testing on web and mobile applications. Much like a human tester, the AI evaluates the current screen context and determines the next most logical action to uncover edge cases, usability gaps, and defects.
Mabl
An AI-native testing platform that focuses on intelligent automation and auto-healing capabilities, enabling teams to maintain stable test suites with minimal effort.
testRigor
A natural language-driven testing platform that allows teams to create and execute tests using plain English, significantly reducing the barrier to automation.
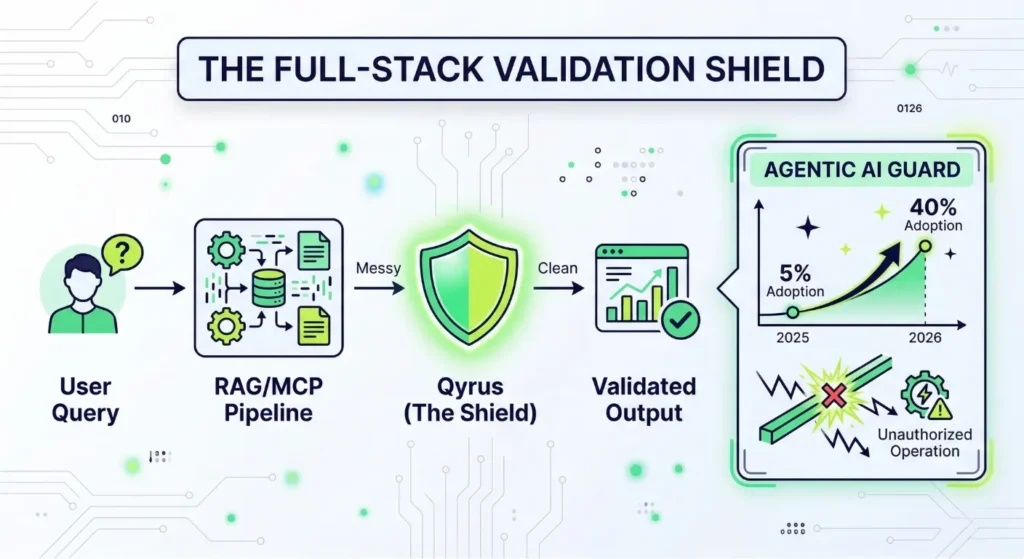
Emerging Agentic Orchestration Platforms
A new category of platforms is emerging that combines:
- Test generation
- Execution orchestration
- Data amplification
- Continuous optimization
These platforms leverage multiple specialized AI agents to navigate applications, generate tests, and adapt to changes autonomously, effectively eliminating manual maintenance cycles.
This shift toward end-to-end orchestration marks the next phase of evolution in software testing.
Preparing Your Team for the Future
Generative AI for testing is redefining how software quality is engineered. It enables faster releases, broader coverage, and a significant reduction in manual effort while addressing long-standing challenges such as test maintenance and data limitations.
The role of the tester is evolving into that of a quality architect—designing intelligent systems, validating outcomes, and guiding continuous improvement.
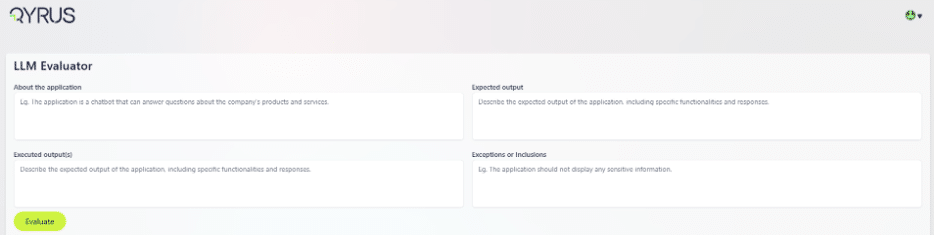
Qyrus accelerates this transformation through its AI Verse, including TestGenerator+ for automated test creation, Echo for scalable synthetic data generation, and LLM Evaluator for semantic validation of AI outputs.
See how Qyrus enables autonomous, AI-driven test orchestration at scale. Request a demo to evaluate real-world impact across your QA pipeline.
FAQs
- How does generative AI for testing differ from traditional AI in QA?
Traditional AI in testing is predictive and analytical, focusing on detecting patterns and anomalies. Generative AI is creation-focused, producing test cases, scripts, and data directly from natural language inputs.
- Can generative AI truly create test cases without human input?
Generative AI can autonomously generate test cases, but a human-in-the-loop approach is essential to validate outputs and ensure alignment with business logic.
- How do I prevent AI hallucinations from creating false test results?
Implement semantic validation layers, define strict guardrails, and continuously evaluate outputs against expected results to ensure accuracy.
- Is it safe to use generative AI with sensitive company data?
Yes. Synthetic data generation enables realistic testing without exposing sensitive information, ensuring compliance with privacy regulations.
- What is the biggest hurdle to adopting generative AI in testing today?
The primary challenge is integrating generative AI into legacy workflows and overcoming test debt. Modern orchestration platforms help address this by enabling autonomous test adaptation and maintenance.
![Featured_Image-LLM_evaluation[1]](https://www.qyrus.com/wp-content/uploads/2026/03/Featured_Image-LLM_evaluation1.webp)