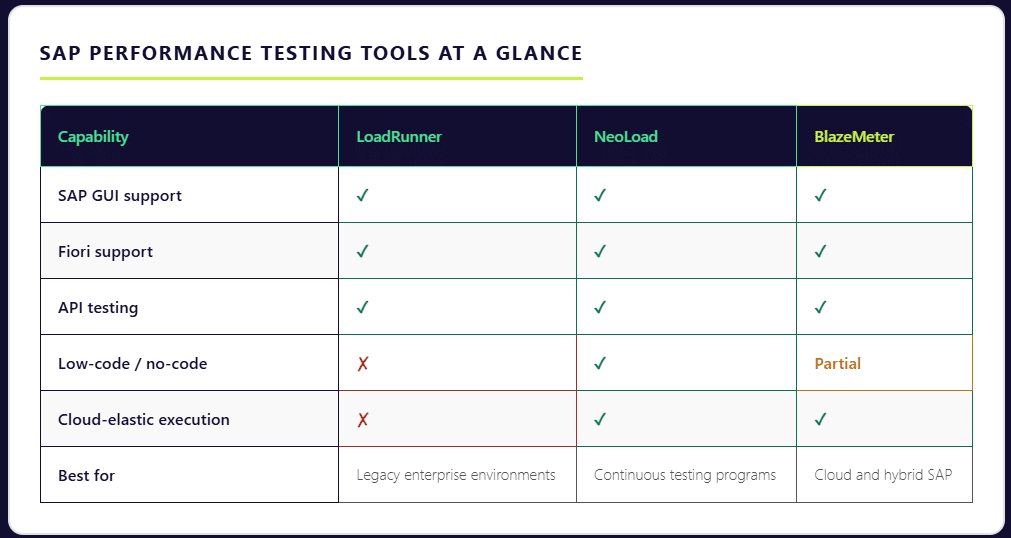
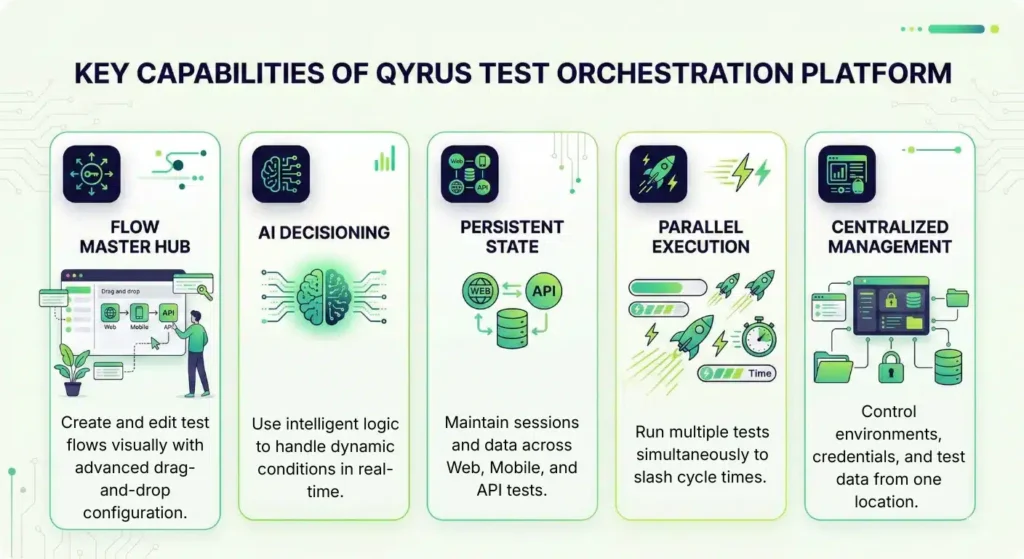
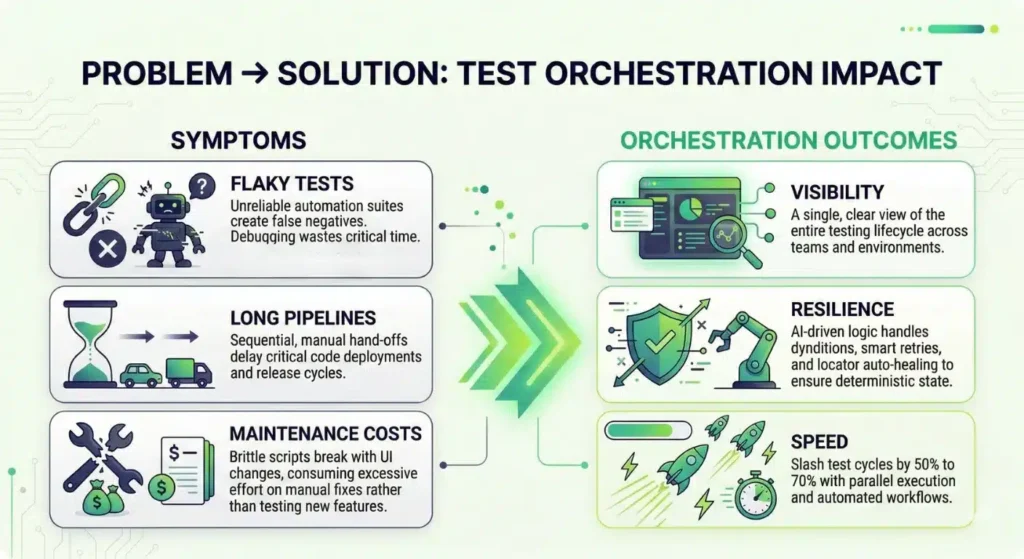
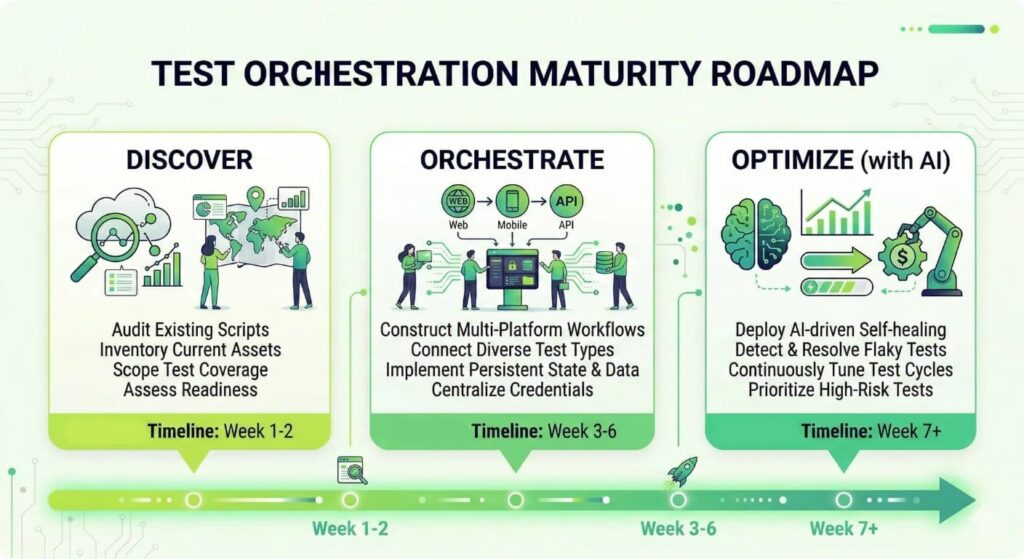
Now let’s unpack what makes each platform worth a closer look — and where they fall short.
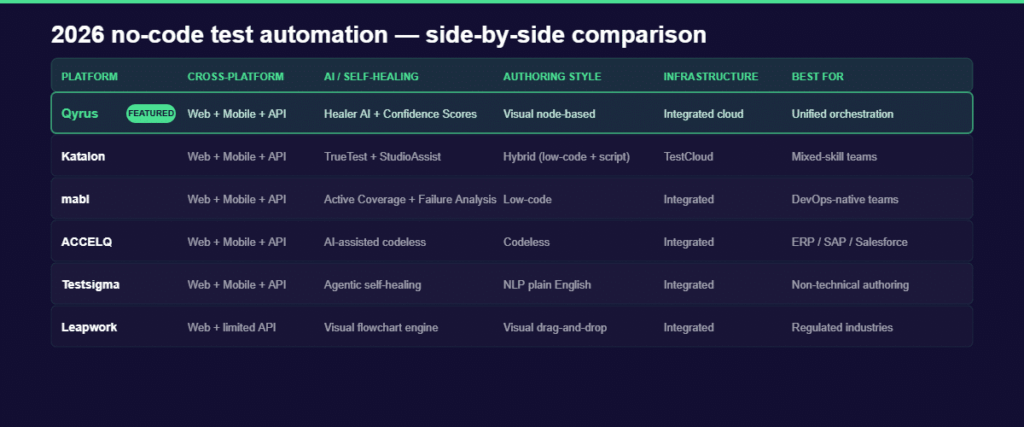
Qyrus — Best for Unified Cross-Platform Orchestration
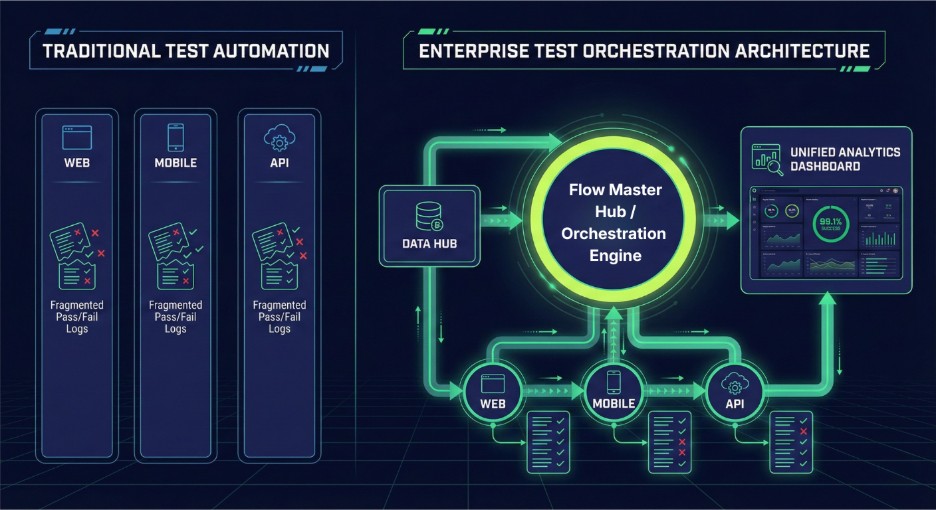
Most codeless testing platforms support web, mobile, and API testing. Fewer of them let those three channels share a single session. That distinction is the core of what Qyrus does differently.
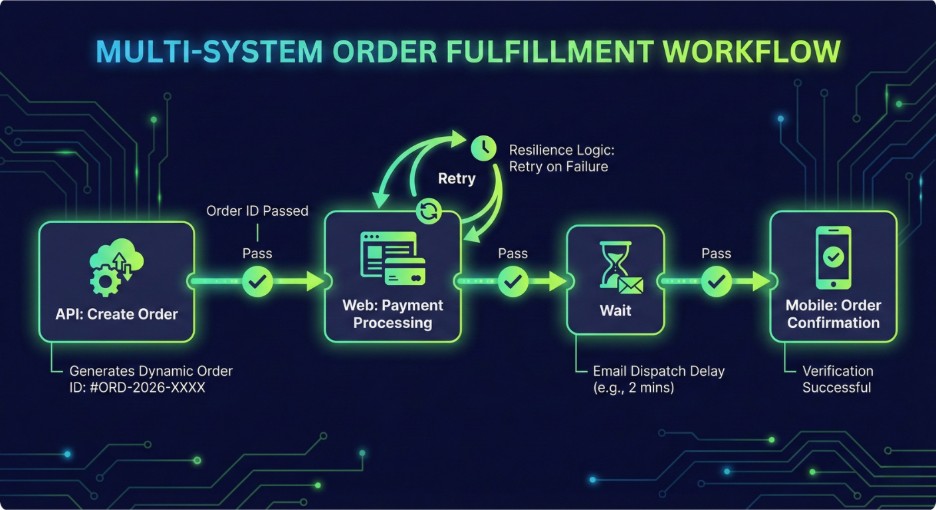
When a test touches multiple systems, a mobile app that triggers an API call that confirms via a web dashboard, most tools require separate projects, manual data exports, and careful re-import of tokens or IDs between stages. Qyrus handles this as a single orchestrated flow. The authentication token from step one is automatically available in step two. The transaction results from step three informs the validation in step four. No manual wiring is required.
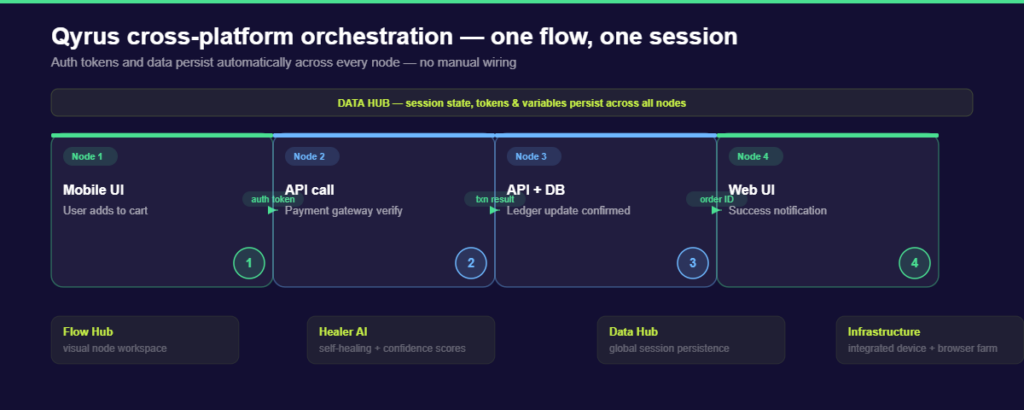
This is the “wiring tax” that Qyrus is designed to eliminate. Here is how the platform’s SEER (Sense, Evaluate, Execute, Report) architecture delivers it:
AIVerse Agents: Qyrus coordinates a population of specialized Single-Use Agents (SUAs)—such as Uxtract and API Builder —coordinated by the SEER orchestration layer.
Nova + Healer AI: Nova is Qyrus’ AI layer for test generation. It suggests assertions from UI interactions and can generate test suites from API discovery using a Chrome extension that captures API calls as a user works through the UI. Healer AI handles maintenance: when a locator breaks due to a UI change, it proposes a fix and assigns a Confidence Score. High-confidence fixes can be auto-applied; lower-confidence fixes queue for human approval.
Beyond testing standard apps, Qyrus is uniquely positioned for the “Agentic Era” by testing the AI itself. It is the only platform in this set that earned a perfect 5.0 from Forrester for testing RAG pipelines and agentic tool calling, capabilities essential for enterprises building and validating their own AI-infused applications.
Integrated infrastructure: Qyrus includes a real device farm and browser cloud within the platform; no separate Sauce Labs or BrowserStack subscription required. For teams testing at scale, this removes one integration dependency from the stack.
On ROI, Qyrus reports a 150% efficiency boost for a banking client as validated in a Forrester TEI study showing a 213% ROI with payback in under six months. Those numbers are worth pressure-testing in a proof of concept, but they reflect the platform’s core pitch: replacing multiple fragmented tools with one orchestrated environment lowers total cost of ownership even when the per-seat licensing looks comparable.
Qyrus is the right choice for QA teams that need to test complex, multi-system user journeys and want to do it without specialized automation engineers gluing tools together. If your testing environment is primarily single-channel — web only, or mobile only — the orchestration depth may be more than you need.
Want to see Qyrus handle your specific cross-platform testing environment? Request a demo.
Katalon — Best for Teams That Still Need a Script Fallback
Katalon has come a long way from its origins as a Selenium wrapper. By 2026, it has matured into the Katalon True Platform, a full quality management system with a credible AI generation story and one of the most capable mobile testing suites in this comparison.
The standout addition in recent versions is TrueTest: a capability that ingests real user session recordings from production and auto-generates corresponding test cases. Instead of QA engineers manually mapping test scenarios, TrueTest continuously expands coverage based on how actual users interact with the application. It shifts the coverage conversation from “how many tests have we written” to “how much of real user behavior is covered.”
For mobile testing specifically, Katalon’s live testing features are genuinely advanced. Biometric authentication simulation, GPS and IP geolocation, camera image injection, and network throttling across 2G, 3G, and LTE — these are capabilities that matter when you are testing applications with location-aware features or connectivity-dependent behaviors.
The honest limitation is Groovy. For complex test logic including conditional flows, custom data manipulation, edge-case assertions, Katalon still routes teams through its Groovy/Java scripting editor. For organizations with technical QA engineers, this is a feature: a scripting fallback when the visual interface hits its limits. For organizations trying to enable business analysts or product managers to write tests independently, it is a bottleneck. The platform is genuinely hybrid, which means it serves mixed-skill teams well and fully non-technical teams less so.
Katalon is the right choice for QA teams with a mix of technical and non-technical testers, particularly those who have existing Selenium or Appium experience they want to preserve alongside newer AI-assisted authoring.
mabl — Best for DevOps-Native Engineering Teams
mabl has built its identity around one principle: serving as an “independent quality reviewer” for AI-coding-agent output. In 2026, that positioning has deepened into a full agentic platform with the strongest developer experience in this comparison.
The most concrete expression of this is mabl’s MCP Server integration, which lets developers interact with the platform directly from their IDE or terminal. Combined with its native Jira integration via Atlassian Rovo, where mabl can generate test cases from Jira tickets automatically, the result is a testing platform that lives inside the development workflow rather than alongside it.
Two capabilities stand out for QA leaders evaluating mabl. Active Coverage means tests evolve automatically as the application UI changes: mabl detects the change, updates the affected tests, and keeps the suite current without manual intervention. Failure Analysis classifies failures before a human investigates, distinguishing genuine regressions from application changes and environmental noise. In high-velocity CI pipelines where flaky tests erode trust in automation, this classification step saves significant engineering time.
For mobile testing, mabl’s Visual Assist finds elements based on visual appearance rather than underlying code. When a mobile layout shifts — a button moves, a form reorganizes — Visual Assist adapts because it reasons about what the element looks like and what it does, not what its ID is.
The limitation to flag honestly: mabl is optimized for developer-QA collaboration in agile teams. Business analysts or non-technical stakeholders who want to author tests independently will find mabl’s interface less accessible than Qyrus’s node-based approach or Testsigma’s NLP authoring. If “democratizing test creation to non-engineers” is a strategic goal, mabl is not the primary tool to get there.
mabl is the right choice for engineering organizations where QA and development share tooling, the CI/CD pipeline runs fast, and the priority is autonomous test maintenance over test authoring accessibility.
ACCELQ, Testsigma, and Leapwork — At a Glance
Three more platforms round out the 2026 no-code test automation landscape, each with a clearly defined niche. For most web, mobile, and API testing environments, the comparison above is the core decision. But for specific use cases, one of these three may be the right fit.
ACCELQ — Best for ERP and Complex Business Process Automation
ACCELQ is built for organizations where the application under test is a complex enterprise system: SAP, Salesforce, Oracle, or a custom ERP. Its codeless engine models business processes at a higher level of abstraction than most tools — you define what the process does, not the individual UI interactions required to execute it.
Its codeless engine models business processes at a higher level of abstraction than most tools — you define what the process does, not the individual UI interactions required to execute it. While ACCELQ remains a dominant choice for Salesforce, Workday, and Oracle, Qyrus has significantly deepened its enterprise utility through specialized SAP capabilities, including Qyrus DataChain and Robotic Smoke Testing.
The productivity numbers ACCELQ publishes are among the strongest in this comparison: 7.5x faster automation development and 72% reduction in maintenance overhead. For teams automating repetitive, process-heavy workflows across enterprise applications, those gains are credible. ACCELQ was also recognized as a leader in the G2 Winter 2026 reports, which reflects strong user satisfaction within its target segment.
Where ACCELQ is less suited: greenfield digital products, consumer-facing web and mobile applications built on modern JavaScript frameworks, or organizations where the primary need is cross-platform orchestration rather than process modeling.
Testsigma — Best for NLP-First, Accessibility-Driven Authoring
Testsigma’s core differentiator is plain-English test authoring. Testers write test steps in natural language — “click the login button,” “verify the order total equals $49.99” — and Testsigma’s NLP engine maps those instructions to executable automation. No code, no visual drag-and-drop, no node configuration.
This makes Testsigma the most accessible platform in this comparison for non-technical contributors: business analysts, product managers, and domain experts who understand what the application should do but have no interest in how to automate it. The platform’s agentic healer claims a 90% reduction in test maintenance, and its cross-platform coverage — web, mobile, and API — is comprehensive.
The platform’s Atto 2.0 (context-aware agentic healer) claims a 90% reduction in maintenance through its specialized Five-Agent model—Generator, Runner, Analyzer, Healer, and Optimizer.
The gap relative to Qyrus is orchestration depth. Testsigma handles each test type well in isolation via its Five-Agent model (Generator, Runner, Analyzer, Healer, and Optimizer). For complex multi-system journeys where session state needs to persist across web, mobile, and API within a single flow, Qyrus’ node-based chaining provides more structural control.
Leapwork — Best for Regulated Industries Requiring Audit Trails
Leapwork’s visual flowchart approach to test automation has found a strong market in regulated industries including financial services, pharma, and healthcare, where auditability, process documentation, and deterministic test paths are requirements, not preferences. Each test in Leapwork is a visible flowchart that non-technical stakeholders can read and validate, which satisfies audit requirements in ways that code-heavy automation cannot.
Its 2026 Continuous Validation Platform extends this positioning into AI-assisted test creation while maintaining the visual transparency that its regulated-industry customer base requires.
The honest limitation: API testing coverage in Leapwork is thinner than the other platforms in this comparison. For organizations whose primary testing need is end-to-end API chain validation or API-first application architecture, Leapwork is not the strongest choice. For regulated organizations testing complex, multi-step business processes through a UI, it is hard to beat.
The Self-Healing Question — What ‘AI-Powered’ Actually Means in 2026
Every platform in this comparison claims AI-powered self-healing. The claim is accurate for all of them, and almost useless as a differentiator because of it. What matters to a QA leader is not whether a platform uses AI for maintenance, but what level of autonomy that AI operates at and what controls exist when it makes decisions.