

The Best End-to-End Testing Tools in 2026: AI-Powered vs. Traditional Frameworks
 Varun RS
Varun RS

Here is a number that should make every engineering leader uncomfortable: a bug caught during requirements costs $100 to fix. The same bug, discovered in production, costs $10,000. That is a 100x multiplier, and according to IBM’s Systems Sciences Institute, it has held true across decades of software development.
Yet despite this well-documented reality, 85% of website bugs are still found by users, not QA teams.
The reason is not a lack of effort. It is a structural mismatch between how fast software is being written and how well teams can test it. AI coding tools like GitHub Copilot and Amazon CodeWhisperer are writing between 20–40% of all new code at major tech companies. Developers ship faster than ever. But testing, anchored to brittle scripts, fragmented toolchains, and manual maintenance cycles, has become the new bottleneck standing between code and confident release.
This is the velocity gap. And it is widening.
In 2026, the question is no longer whether to automate end-to-end testing. It is which approach actually works at scale: the open-source code-first frameworks that dominate developer surveys, or the emerging generation of AI-powered platforms that promise to do far more than run scripts.
This guide cuts through the noise. We compare the leading end-to-end testing tools including Playwright, Cypress, Selenium, and AI-powered alternatives, on the dimensions that matter to real teams: maintenance burden, CI/CD integration, cross-platform coverage, and long-term ROI. Whether you are a QA engineer evaluating your next framework, a developer tired of fixing flaky tests, or an engineering manager building a business case for tooling investment, you will find a clear, honest picture of where the market stands and where it is going.

What Is End-to-End Testing (And Why Traditional Approaches Are Failing)
End-to-end (E2E) testing validates a complete user journey, from the first click through backend processing, database updates, and confirmation screens, as a single, continuous flow. Unlike unit tests, which verify individual functions, or integration tests, which check how modules interact, E2E tests simulate real user behavior across interconnected systems. They answer the question every business actually cares about: does this work, end to end, the way a real user would experience it?
The testing pyramid places E2E tests at the top for a reason. They offer the most comprehensive validation but also carry the highest cost: slower to run, harder to build, and notoriously difficult to maintain as applications change.
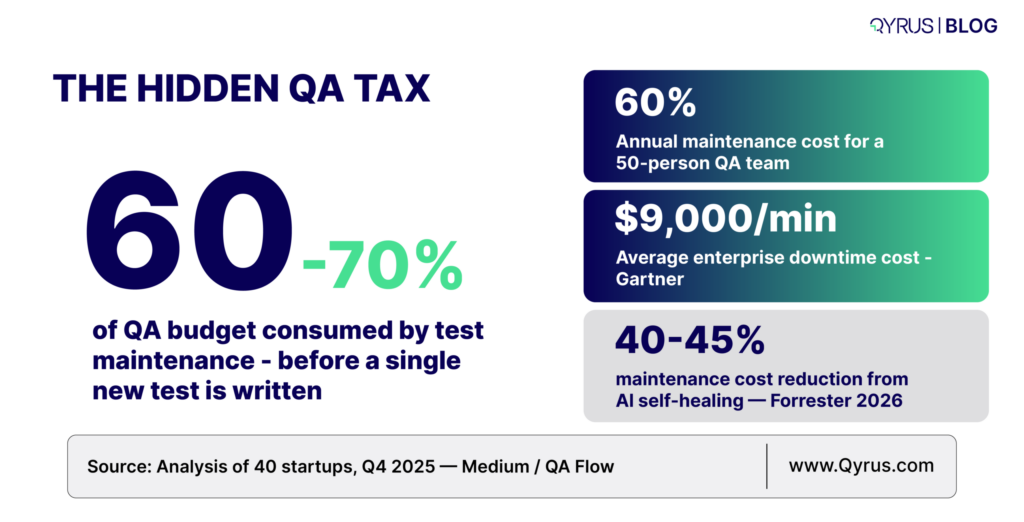
That maintenance challenge is where most teams quietly lose the plot. According to analysis of 40 startups conducted in Q4 2025, teams spend 60–70% of QA time on test upkeep, with only 30–40% going to new coverage or actual results review. The consequence: enormous engineering investment producing diminishing returns.
Maintenance burden: 60–70% of QA time is spent on test upkeep, not new coveragehttps://medium.com/qa-flow/the-hidden-test-automation-maintenance-cost-consuming-50-of-qa-time-a8a462cd9084
Production cost multiplier: A bug caught in requirements costs $100. The same bug in production costs $10,000 which is a 100x difference. https://betterqa.co/bug-fixing-costs-throughout-sdlc/User-detected bugs: 85% of website bugs are found by users, not QA teams.
https://dev.to/esha_suchana_3514f571649c/the-hidden-24-trillion-crisis-why-software-quality-cant-wait-57eiDowntime cost: Average enterprise downtime costs $9,000 per minutehttps://testomat.io/blog/software-bug-cost/
The “shift-left” movement exists precisely because of these economics: catch defects early, when they cost almost nothing to fix, rather than in production, where they cost everything. But shifting left requires test automation that actually runs reliably in CI/CD pipelines, integrates with GitHub Actions and Azure DevOps, and does not collapse every time a developer renames a button.
Traditional E2E testing tools were not built for this reality. They were built for a world where applications changed slowly, QA engineers had months to build scripts, and the average test suite had hundreds, not thousands, of tests to maintain. That world is gone.
Playwright, Cypress, and Selenium: Strengths, Limitations, and When to Use Each
Three frameworks dominate the end-to-end testing conversation in 2026. Each earns its place for specific use cases. Each also carries real limitations that enterprise teams routinely discover too late.
Playwright
Built by Microsoft and now holding 45.1% adoption among QA professionals, with a 91% satisfaction rating in the State of JS 2025 survey, the widest gap over Cypress ever recorded, Playwright has become the go-to framework for new projects in 2026.
Its advantages are substantial. Playwright supports Chromium, Firefox, and WebKit natively, meaning true cross-browser coverage including Safari on a single codebase. It is 3.2x faster than Selenium in parallel execution, offers built-in parallelization at zero additional cost, and its auto-wait functionality eliminates most timing-related flaky tests. Multi-language support, including JavaScript, TypeScript, Python, Java, and C#, makes it accessible to polyglot teams.
Playwright’s limitations matter for enterprise buyers. It requires coding expertise — business analysts and manual testers cannot create or maintain tests without developer support. It covers web only; mobile native apps, desktop applications, and SAP/ERP systems are entirely out of scope. There is no self-healing: every UI change that breaks a locator requires manual triage and repair. And while the framework is free, its value depends entirely on the engineering time needed to build and maintain scripts.
Best for: JavaScript/TypeScript teams building modern web apps who need cross-browser coverage and strong CI/CD integration.
Cypress
Cypress pioneered the developer-friendly testing movement and still holds a loyal following, currently at 14.4% adoption, among frontend JavaScript teams. Its in-browser execution model delivers the most intuitive debugging experience in the category: time-travel debugging that lets you step backward through DOM snapshots is something neither Playwright nor Selenium offers natively.
The trade-offs are significant. Cypress supports Chromium-based browsers only, no Firefox WebKit, no Safari. It does not support mobile app testing, desktop apps, or any ERP platform. Its architecture limits tests to single-domain scenarios, which creates real friction in enterprise applications that span multiple subdomains or authentication systems. Its cloud parallelization requires a paid subscription: teams running 1,000 tests daily can expect to spend $400–800 per month on Cypress Cloud, compared to near-zero incremental cost on Playwright.
Best for: Frontend-focused JavaScript teams who value interactive debugging and work exclusively within a single-domain web app.
Selenium
Selenium has been the backbone of enterprise browser automation for nearly two decades. Over 31,000 companies report active Selenium usage. It supports every major programming language, every major browser, and virtually every CI/CD tool in the market, and it is entirely free.
But Selenium’s market share has declined to 22.1% in 2026 for a reason. Its WebDriver architecture introduces HTTP overhead that makes it measurably slower than Playwright. More critically, Selenium has no self-healing whatsoever: every UI change requires manual locator updates across every affected test. For large enterprises with thousands of tests, this maintenance burden consumes entire QA teams. Reporting, test management, and parallel execution all require additional third-party tools assembled from scratch.
Best for: Large enterprises with established Java, Python, or C# test suites, polyglot teams, and the engineering capacity to manage a high-maintenance framework.
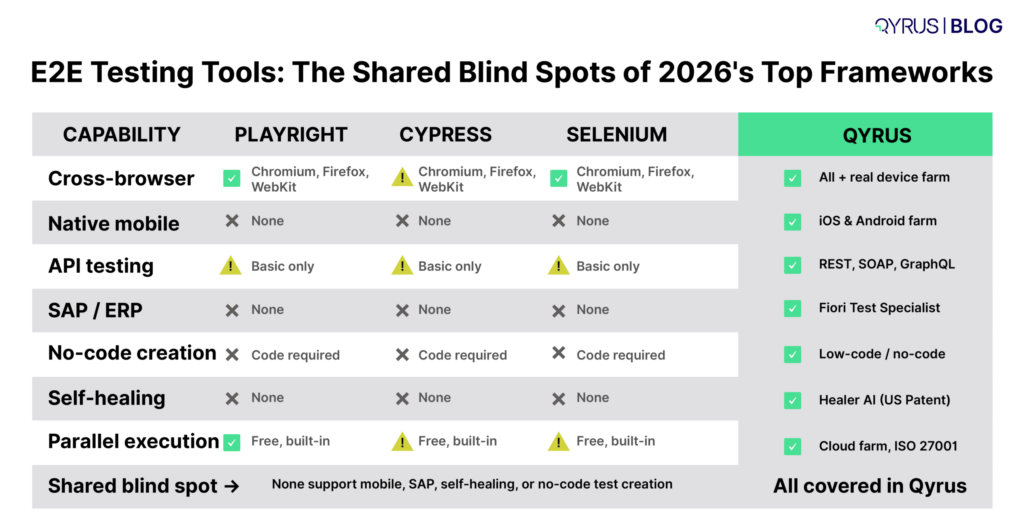
The three frameworks compared across the dimensions enterprise teams care about most:
Dimension | Playwright | Cypress | Selenium |
Browser Support | ✅ Chromium, Firefox, WebKit | ⚠️ Chromium only | ✅ All major browsers |
Mobile Testing | ❌ Web emulation only | ❌ Not supported | ❌ Not supported |
API Testing | ⚠️ Basic support | ⚠️ Basic support | ⚠️ Basic support |
SAP / ERP Testing | ❌ None | ❌ None | ❌ None |
Coding Required | ⚠️ Yes (JS/TS/Py/Java/C#) | ⚠️ Yes (JavaScript) | ⚠️ Yes (multi-language) |
Parallel Execution | ✅ Built-in, free | ⚠️ Paid cloud tier | ⚠️ Requires Selenium Grid |
Self-Healing | ❌ None | ❌ None | ❌ None |
CI/CD Integration | ✅ Native (GitHub Actions, Azure DevOps) | ✅ Good (cloud dashboard) | ✅ Via plugins |
The shared blind spot across all three frameworks is not a flaw you can engineer around, it is an architectural reality. None offers unified coverage across Web, Mobile, API, Desktop, and SAP. None provides self-healing automation. None can generate tests from a Jira ticket or a natural language description. For teams whose testing scope ends at the browser, these frameworks deliver real value. For enterprises validating end-to-end business processes that span ERP systems, mobile apps, APIs, and web frontends, they are the wrong foundation.
Why Most Teams Are Paying More Than They Think for E2E Testing
Open-source frameworks appear free. They are not. The license costs nothing; the engineering time to build, run, and maintain them costs everything.
The average enterprise QA team running a mature Selenium or Playwright suite does not use one tool, it uses five. Selenium or Playwright handles web UI. Postman or a REST Assured library handles API testing. Applitools or Percy handles visual regression. TestRail or Jira manages test cases and results. Each tool has its own license, its own learning curve, its own reporting format, and its own maintenance overhead. Results from these tools exist in different systems, require manual correlation, and cannot produce a unified picture of end-to-end coverage.
The maintenance bill compounds as test suites grow. Research across enterprise QA teams puts the figure starkly: a 50-person QA organization with a 70% maintenance burden has 35 engineers spending their entire working time keeping existing tests functional, at an average cost of $100,000 per engineer, that is $3.5 million annually spent on maintenance rather than new coverage.
Annual maintenance cost: A 50-person QA team burns approximately $3.5M per year on test maintenance alonehttps://www.virtuosoqa.com/post/intelligent-test-maintenance
Self-healing ROI: Forrester data puts the maintenance cost reduction from self-healing tests at 40–45%https://brijeshdeb.medium.com/top-trends-in-testing-in-2026-and-what-does-it-mean-for-testers-and-business-leaders-a1a44bd64761
Market growth: The automation testing market reached $40.44B in 2026 and is heading to $78.94B by 2031 at 14.32% CAGRhttps://www.mordorintelligence.com/industry-reports/automation-testing-market
AI adoption: 67% of QA teams now use at least one AI-powered testing tool — up from 21% in 2024https://qasphere.com/blog/ai-in-software-testing/
Flaky tests compound the damage further. When test results are unreliable, engineering teams stop trusting CI/CD pipelines. They reintroduce manual validation steps. They delay releases “just to be safe.” The automation that was supposed to accelerate delivery becomes another bottleneck, and the test suite becomes a liability rather than an asset.
The answer is not a better open-source framework. Playwright is already excellent at what it does. Selenium is already mature. The answer is a fundamentally different architecture, one built for the realities of 2026: heterogeneous application stacks, AI-accelerated development cycles, non-technical team members who understand business processes but cannot write JavaScript, and enterprise deployments that span SAP, Salesforce, mobile apps, and custom web applications in a single end-to-end flow.
The New Generation of E2E Testing Tools: AI-Powered, Agentic, and Unified
“AI-powered” has become one of the most overused labels in the testing industry. Almost every tool now claims it. Most mean something narrow: autocomplete for test scripts, or a visual recorder with an AI icon. The distinction that matters is not whether a tool uses AI, it is what the AI actually does and at what stage of the testing lifecycle it operates.
Genuinely agentic AI testing platforms do something categorically different. They do not wait to be told what to test. They sense changes in the development environment, a new commit to GitHub, a design update in Figma, a modified Jira story, and respond autonomously: analyzing impact, selecting relevant tests, executing them in parallel, self-healing broken locators, and delivering results back into the CI/CD pipeline before a human has reviewed a single line of changed code.
The market signal is unambiguous. Gartner forecasts that 40% of enterprise applications will include task-specific AI agents by the end of 2026, up from less than 5% in 2025. The World Quality Report 2025–26 found 89% of organizations piloting or deploying generative AI in quality engineering, but only 15% have achieved enterprise-scale deployment. That gap between pilot and production is where the competitive advantage lives.
Three capabilities separate genuine AI-native platforms from AI-washed frameworks:
- Self-healing locators: When UI elements change, the platform automatically identifies and updates the affected locators, no manual triage, no broken pipelines. Forrester data puts the maintenance cost reduction from self-healing at 40–45%.
- Autonomous test generation: Tests created from Jira tickets, natural language descriptions, Figma designs, or existing scripts, not from hand-written code. This democratizes testing: business analysts who understand workflows can create coverage without engineering degrees.
- Unified coverage: A single platform validating Web, Mobile, API, Desktop, SAP, and Data in one continuous flow, eliminating the fragmented toolchain that fragments results, multiplies maintenance, and obscures the true picture of end-to-end quality.
The codeless testing segment reflects this shift directly: 39% of companies are now actively evaluating codeless automation tools, according to recent market analysis. The driver is not cost savings alone, it is the recognition that the skills needed to understand business processes and the skills needed to write automation scripts rarely overlap.
For enterprise teams managing SAP S/4HANA landscapes, Salesforce environments, or cross-platform mobile and web applications, the calculus is clear: a unified AI platform that maintains its own tests costs less over three years than an assembly of open-source frameworks that demand constant human maintenance. The question is which platform delivers that promise at enterprise scale.
How Qyrus Delivers True End-to-End Testing — Across Every Layer of Your Stack
Most end-to-end testing platforms validate one layer of the stack. Qyrus validates all of them.
Qyrus is a unified, AI-powered testing platform that covers Web, Mobile, API, Desktop, SAP, and Data testing in a single interface with no fragmented toolchain, no manual correlation across systems, and no separate license for each testing discipline. It is recognized by Forrester, Gartner, and ISG as a leader in intelligent automation and autonomous testing.
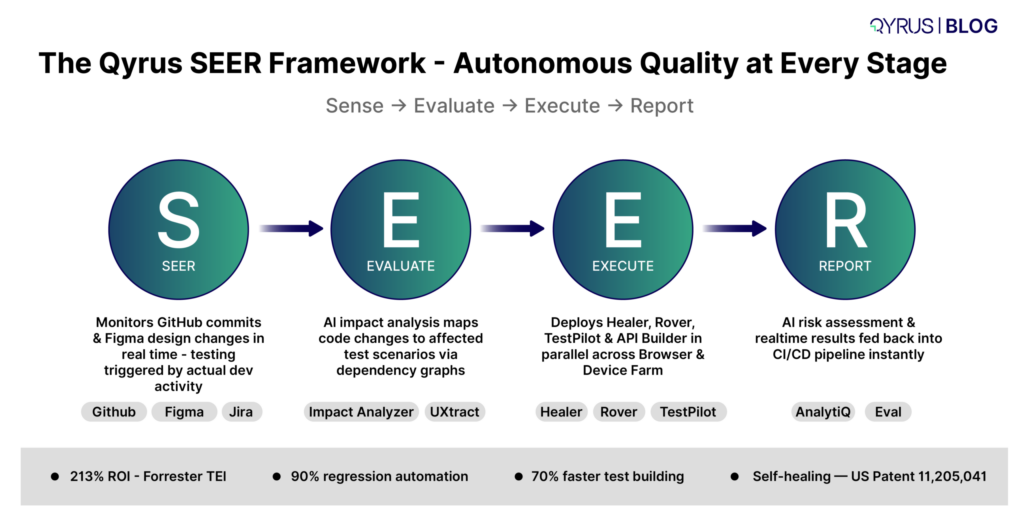
The SEER Framework: Autonomous Quality at Every Stage
At the core of Qyrus is the industry-first SEER (Sense, Evaluate, Execute, Report) framework, an autonomous AI orchestration engine that manages the entire testing lifecycle as a continuous feedback loop, not a scheduled event.
- Sense: Qyrus continuously monitors GitHub repositories for commits, merges, and pull requests, and observes design changes in Figma in real time. Testing is triggered by actual development activity not a calendar.
- Evaluate: Specialized AI agents perform automated impact analysis using static analysis and dependency graphs, mapping code or design changes to the specific API and UI test scenarios most likely to be affected. Only relevant tests run, not the entire regression suite.
- Execute: The platform automatically deploys the right agent for the right job: API Bots for backend validation, the Qyrus Test Pilot (QTP) for frontend UI testing, Rover for autonomous exploratory coverage, and Healer for self-healing maintenance. Tests run in parallel across a scalable, ISO 27001 and SOC 2 Type 2 compliant browser and device farm.
- Report: Results are delivered in real time back into the DevOps pipeline, detailed coverage metrics, step-level screenshots, video recordings, and AI-driven risk assessments, so teams know not just what failed, but what to fix first.
Single-Use AI Agents: A Specialist for Every Testing Challenge
Where most platforms bolt AI onto existing workflows, Qyrus deploys purpose-built Single-Use Agents (SUAs), each an expert in a specific domain:
- Healer (US Patent 11,205,041 B2): When UI elements change, Healer automatically analyses the update and repairs affected test scripts. Self-healing, not just self-flagging. This directly attacks the 60–70% maintenance burden that drains enterprise QA budgets.
- NOVA: Reads Jira tickets, Azure DevOps stories, or plain-text descriptions and automatically generates comprehensive functional test scenarios. Business teams participate in QA from day one.
- TestGenerator+: Analyses existing test scripts and generates new scenarios to fill coverage gaps, categorized by criticality ensuring regression suites stay comprehensive as applications evolve.
- Rover: An autonomous exploratory testing engine that navigates applications without human direction, identifying anomalies, crashes, and bugs in areas scripted tests would never reach.
- API Builder: Generates fully virtualised, mock APIs from natural language descriptions, enabling backend validation independent of third-party system availability.
SAP Testing: The Enterprise Differentiator No Competitor Touches
For organizations running SAP S/4HANA, Fiori, SuccessFactors, or Ariba, Qyrus offers capabilities that Playwright, Cypress, and Selenium cannot begin to match.
The Fiori Test Specialist reverse-engineers SAP application source code alongside functional specifications and existing manual test cases, generating end-to-end test scripts that understand SAP business processes, not just UI interactions. The proprietary Qyrus SAP Scribe, custom ERP-aware AI models fine-tuned to each customer’s SAP landscape, eliminates the brittle XPath locators that plague traditional SAP automation, replacing them with dynamic object recognition that adapts to metadata changes.
The platform also supports cross-application orchestration: a single E2E test flow can span Salesforce, SAP, and Ariba across UI, API, and backend layers simultaneously. Prebuilt business process packs cover O2C, P2P, H2R, and PM flows out of the box.
Test Orchestration: Visual E2E Flow Building for Complex Business Processes
For teams building complex, multi-platform end-to-end business process tests, the Flow Hub provides a drag-and-drop visual canvas for orchestrating Web, Mobile, and API test scripts into a single continuous workflow. SmartFlow Conditional Mapping adapts to live conditions during execution, rerouting tests dynamically if a user fails a login or a transaction lacks balance, without manual script intervention.
Seamless CI/CD and Ecosystem Integration
Qyrus integrates natively with Jenkins, Azure DevOps, Bitrise, TeamCity, and Concourse for CI/CD pipeline execution, and with GitHub and Bitbucket for version control. Test management integrations cover Jira, XRay, and TestRail. Communication integrations include Slack and Microsoft Teams. Tests can be triggered automatically on every commit, scheduled for recurring execution, or run in parallel across the Browser and Device Farm, over 99.9% real device availability, with ISO 27001 and SOC 2 Type 2 compliance.
The Numbers: What Qyrus Delivers
- ROI: 213% return on investment with a payback period of less than 6 months (Forrester Total Economic Impact study).https://www.qyrus.com/post/forrester-report-tei-2024/
- Regression automation: 90% automation of manual regression test cases
- Production incidents: 50% reduction in production incidents and downtime through proactive AI defect detection
- Test building time: 70% reduction in test building time through AI-driven and codeless features
- Test case creation: ~80% faster complex test case creation
- Defect leakage: 80% reduction in defect leakage
- Time to market: 36% faster time to market
These are not framework benchmarks. They are business outcomes with measurable differences in production incident rates, release velocity, and total cost of ownership that translate directly to competitive advantage. A Forrester TEI study commissioned on Qyrus found a 213% ROI with payback in under six months, validated by Shawbrook Bank’s 200% ROI within 12 months of deployment.

How to Choose the Right End-to-End Testing Tool in 2026
The right E2E testing tool depends on your team’s scope, skills, and scale, not on which framework tops a developer survey. Five questions will clarify the decision faster than any feature comparison:
- Do we need web-only coverage, or do our E2E tests need to span Mobile, API, Desktop, or SAP/ERP systems? If the answer is web-only with a coding-fluent team, Playwright is likely your strongest starting point. If your E2E flows cross system boundaries, open-source frameworks will force you to build a fragmented toolchain that multiplies maintenance overhead.
- Can our non-technical team members, business analysts, manual testers, domain experts, create and maintain tests? If your QA capacity is gated by automation engineering bandwidth, a codeless or low-code AI platform expands that capacity without proportional headcount growth.
- How much of our current QA budget is being consumed by test maintenance? If the answer is more than 40%, the actual cost of your “free” framework already exceeds most enterprise platform licensing fees. Calculate your three-year total cost of ownership before comparing tools on license price alone.
- Does our CI/CD pipeline need native integration with GitHub Actions, Azure DevOps, or Jenkins, and do we need parallel execution without paying per-run fees? All major platforms offer CI/CD integration, but the depth, cost, and configuration complexity vary significantly.
- Are we prepared to manage, integrate, and train on multiple tools, or do we need a unified platform that covers the full testing lifecycle? Fragmented toolchains work for mature engineering teams with specialized skill sets. Unified platforms are better suited to mixed teams that need one system to own from test creation to defect reporting.
A simple guide to match team profile to tool choice:
If your team looks like this… | Consider this approach |
JavaScript/TypeScript developers, web-only apps, cross-browser needs | Playwright (free, fast, excellent DX) |
Frontend JS team, Chromium only, heavy debugging needs | Cypress (best interactive debugging experience) |
Polyglot enterprise team, legacy Java/C# test suites | Selenium (mature ecosystem, broad language support) |
Enterprise team, Web + Mobile + API + SAP, mixed skills, high maintenance burden, need unified ROI | Qyrus, AI-powered unified platform with SEER framework, self-healing, and 213% Forrester-validated ROI |
It is also worth acknowledging what this guide is not arguing. Playwright and Cypress are genuinely strong tools for the use cases they were designed for. The engineering teams at companies like Shopify, Vercel, and Stripe who built their E2E suites on Playwright made sound decisions. The argument here is not that open-source frameworks are bad, it is that they are increasingly insufficient as the sole testing infrastructure for enterprises whose applications span systems, teams, and technology stacks that no single framework was ever designed to cover.
Frequently Asked Questions
1: What is the difference between end-to-end testing and integration testing?
Integration testing checks whether two or more modules work correctly when combined, it validates specific connection points between components. End-to-end testing goes further, validating an entire user journey from the first interaction through every system it touches, including the UI, APIs, databases, and backend services, exactly as a real user would experience it. Think of integration testing as checking that two puzzle pieces fit; E2E testing confirms the finished puzzle makes the right picture.
2: Is Playwright better than Selenium for end-to-end testing in 2026?
For most new projects, yes. Playwright holds 45.1% adoption among QA professionals in 2026, is 3.2x faster than Selenium in parallel execution, and offers built-in cross-browser support across Chromium, Firefox, and WebKit at zero additional cost. Selenium remains the stronger choice for large enterprises with established Java, Python, or C# test suites and polyglot engineering teams. The honest answer depends on your existing stack, but Playwright wins on speed, modern API design, and CI/CD integration for greenfield projects.
3: What does “self-healing” mean in end-to-end testing tools?
Self-healing refers to a platform’s ability to automatically detect and repair broken test locators when the application’s UI changes, without human intervention. In traditional frameworks like Selenium, Cypress, and Playwright, a renamed button ID or rearranged form element breaks the test and requires a developer to manually update the script. Self-healing tools, powered by AI, identify the changed element, find the correct new locator, and update the test automatically. Forrester data shows self-healing reduces test maintenance costs by 40–45%, directly attacking the biggest hidden cost in enterprise QA.
4: Can end-to-end testing tools integrate with CI/CD pipelines like GitHub Actions and Azure DevOps?
Yes, and seamless CI/CD integration is now a baseline requirement, not a differentiator. Playwright, Cypress, and Selenium all integrate with GitHub Actions, Azure DevOps, Jenkins, and other major CI/CD platforms, triggering test runs automatically on code commits. AI-powered platforms like Qyrus go a step further: they integrate directly into the pipeline and use the commit as a trigger for autonomous impact analysis, parallel test execution, and real-time reporting back to the team, eliminating manual hand-offs entirely.
5: Which end-to-end testing tool works best for SAP and enterprise ERP applications?
None of the major open-source frameworks including Playwright, Cypress, or Selenium, natively support SAP Fiori, S/4HANA, or other ERP platforms. They rely on generic browser automation that breaks frequently against SAP’s dynamically generated control IDs and metadata-driven UI. Purpose-built platforms like Qyrus, with the Fiori Test Specialist and SAP Scribe (custom ERP-aware AI models fine-tuned to each customer’s SAP landscape), are designed specifically for this challenge, eliminating brittle XPath locators, supporting cross-application orchestration across SAP, Salesforce, and Ariba, and generating end-to-end test scripts that understand SAP business processes, not just UI clicks.
The Future of End-to-End Testing Is Autonomous; Are You Ready?
The best end-to-end testing tools in 2026 are not just frameworks that run scripts faster. They are intelligent platforms that watch for change, assess impact, execute the right tests autonomously, self-heal when something breaks, and report back to every stakeholder who needs to know, all without a human deciding what to test or manually fixing what breaks.
The economics of traditional E2E testing have always been difficult. The maintenance burden, 60–70% of QA budget consumed before a single new test is written, has quietly made many automation initiatives liabilities rather than assets. AI-native platforms flip that equation: the cost of testing falls as the platform gets smarter, rather than rising as the test suite grows.
For teams still evaluating Playwright against Cypress, the comparison is worth making carefully, and both are strong for their intended context. But for enterprises whose definition of end-to-end includes SAP transactions, mobile native apps, REST APIs, and web frontends in a single validated flow, the comparison is not really between frameworks at all. It is between a fragmented assembly of tools that each cover one layer, and a unified platform that covers everything.
Qyrus delivers 213% ROI (Forrester TEI), 80% reduction in defect leakage, 36% faster time to market, and 90% automation of manual regression cases, not as theoretical benchmarks, but as outcomes validated by enterprise customers across BFSI, manufacturing, retail, and SAP-heavy industries.
The velocity gap between development speed and QA capacity is not closing on its own. The teams that close it first will ship faster, with fewer production incidents, and at lower total cost than their competitors. That is not a prediction, it is already happening.
See how Qyrus transforms end-to-end testing for enterprise teams. Request a personalised demo →

 July 23, 2026
July 23, 2026  18 min
18 min





