Zillow’s iBuying division collapsed after losing a staggering $881 million on housing models trained on inconsistent data.
This catastrophe proves that even the most advanced machine learning fails when built on a foundation of flawed information. Stanford AI Professor Andrew Ng captures the urgency: “If 80 percent of our work is data preparation, then ensuring data quality is the most critical task”.
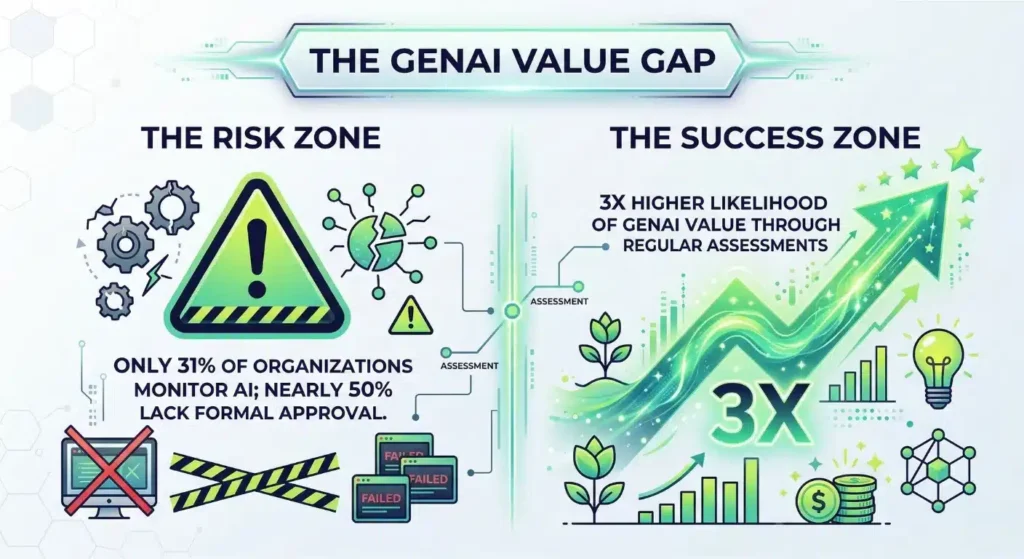
Organizations now face an average annual loss of $15 million due to poor information quality. Most enterprises struggle with these costs because they lack sophisticated data quality testing tools to catch errors early.
Relying on manual checks in high-speed pipelines creates massive blind spots that invite financial disasters. Professional data quality validation in ETL processes must move beyond a reactive “firefighting” mindset. Precision requires a proactive strategy that protects your capital and restores trust in your digital insights.

The 1,000x Multiplier: Why Your Budget Cannot Survive Fragmented Quality
Ignoring quality creates a financial sinkhole that scales with terrifying speed. The industry follows a brutal economic principle known as the Rule of 100. A single defect that costs $100 to fix during the requirements phase balloons into a monster as it moves through your pipeline. That same bug costs $1,000 during coding and $10,000 during system integration. If it escapes to User Acceptance Testing, the bill hits $50,000. Once that flaw goes live in production, you face a recovery cost of $100,000 or more.
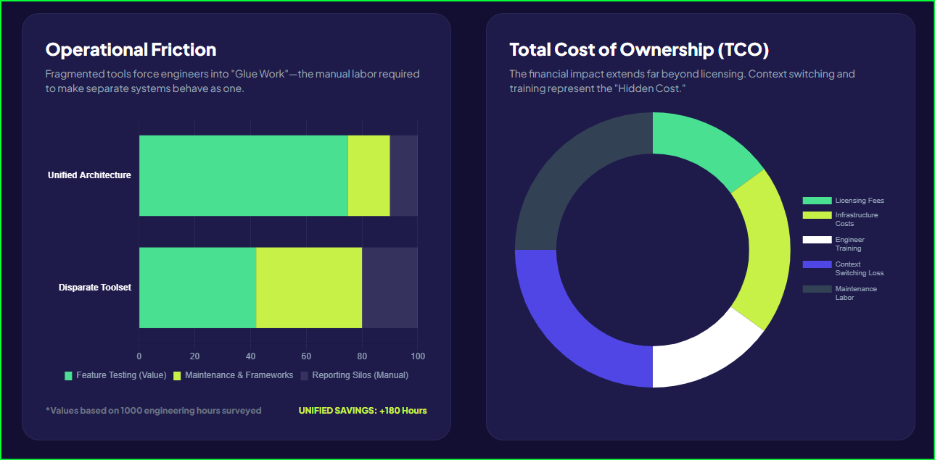
Enterprises currently hemorrhage capital through maintenance overhead. Industry surveys report that keeping existing tests functional consumes up to 50% of the total test automation budget and 60-70% of resources. This means you spend most of your resources just maintaining the status quo instead of building new value. Fragmented ETL testing automation tools aggravate this problem by forcing engineers to update multiple disconnected scripts every time a schema changes.
The financial contrast is stark. Managing disparate tools for a 50-person QA team costs an average of $4.3 million annually, according to our estimates. Switching to a unified platform reduces this cost to $2.1 million—a 51% reduction in total expenditure.
Breakdown of Annual Costs (50-Person Team)
| Cost Category |
Disparate Tools |
Unified Platform |
Annual Savings |
| Personnel & Maintenance |
$3,500,000 |
$1,750,000 |
$1,750,000 (50%) |
| Infrastructure |
$500,000 |
$250,000 |
$250,000 (50%) |
| Tool Licenses |
$200,000 |
$75,000 |
$125,000 (62.5%) |
| Training & Certification |
$100,000 |
$50,000 |
$50,000 (50%) |
| Total Annual Cost |
$4,300,000 |
$2,125,000 |
$2,175,000 (51%) |
Implementing a robust ETL data testing framework allows you to stop paying the “Fragmentation Tax” and start investing in innovation. Without automated data quality checks, your organization remains vulnerable to the exponential costs of escaped defects.
Tool Sprawl is the Silent Productivity Killer in Your Pipeline
Fragmented workflows force your engineers to act as human integration buses. When you use separate platforms for web, mobile, and APIs, your team toggles between applications 1,200+ times daily. This constant context switching creates a massive cognitive tax, slashing productivity by 20% to 80%. For a ten-person team, this translates to 10 to 20 hours of lost work every single day.

Disconnected ETL testing automation tools also create dangerous blind spots. About 40% of production incidents stem from untested interactions between different layers of the software stack. Siloed suites often miss these UI-to-API mismatches because they only validate one piece of the puzzle at a time. Furthermore, data corruption in multi-step flows accounts for 25% of production bugs. Without an integrated ETL data testing framework, your team cannot verify a complete journey from the front end to the database.
Fragility in your CI/CD pipeline often leads to the “Pink Build” phenomenon. This happens when builds fail due to flaky tooling rather than actual code defects, causing engineers to ignore red flags. Maintaining these custom integrations costs an additional 10% to 20% of your initial license fees every year. To regain velocity, you must move toward automated data quality checks that run within a single, unified interface. Consolidation allows you to replace multiple expensive data quality testing tools with a platform that delivers data quality validation in ETL across the entire enterprise.
Sifting Through the Contenders in the Quality Arena
Choosing the right partner for your data strategy requires a clear view of the current market. Every organization has unique needs, but the goal remains the same: eliminating defects before they poison your decision-making. While specialized tools offer depth in specific areas, Qyrus takes a different path by providing a unified TestOS that handles web, mobile, API, and data testing within a single ecosystem.
Tricentis
Tricentis currently dominates the enterprise space with an estimated annual recurring revenue of $400-$425 million. It maintains a massive footprint, serving over 60% of the Fortune 500. Organizations deep in the SAP ecosystem often choose Tricentis for its specialized integration and model-based automation. However, its premium pricing and high complexity can feel like overkill for teams seeking agility.
Read the full breakdown: Qyrus vs. Tricentis: Enterprise Scale vs. Unified Agility
QuerySurge
If your primary concern is the sheer variety of data sources, QuerySurge stands out with over 200 connectors. It functions primarily as a specialist for data warehouse and ETL validation. While it offers the strongest DevOps for Data capabilities with 60+ API calls, it lacks the ability to test the UI and mobile layers that actually generate that data.
Read the full breakdown: Qyrus vs. QuerySurge: Specialist Connectivity vs. Full-Stack Coverage
iCEDQ
iCEDQ focuses on high-volume monitoring and rules-based automated data quality checks. Its in-memory engine can process billions of records, making it a favorite for teams with massive production monitoring requirements. Despite its power, a steeper learning curve and a lack of modern generative AI features may slow down teams trying to shift quality left.
Read the full breakdown: Qyrus vs. iCEDQ: Shifting Quality Left in the DataOps Pipeline
Datagaps
Datagaps offers a visual builder for ETL testing automation tools and maintains a strong partnership with the Informatica ecosystem. It excels at baselining for incremental ETL and supporting cloud data platforms. However, it currently possesses fewer enterprise integrations and a less mature AI feature set than more unified data quality testing tools.
Read the full breakdown: Qyrus vs. Datagaps: Modernizing Quality for Cloud-Native Data
Informatica Data Validation
Informatica remains a global leader in data management, with a total revenue of approximately $1.6 billion. Its data validation module provides a natural extension for organizations already using their broader suite for data quality validation in ETL.
While these specialists solve pieces of the puzzle, Qyrus delivers a comprehensive ETL data testing framework that bridges the gap between your applications and your data.
The End of Guesswork: Scaling Data Trust with Unified Intelligence
Qyrus redefines the potential of modern data quality testing tools by replacing fragmented workflows with a single, unified TestOS. This platform allows your team to validate information across the entire software stack—Web, Mobile, API, and Data—without writing a single line of code. Instead of wrestling with brittle scripts that break during every update, engineers use a visual designer to build a resilient ETL data testing framework.
The platform operates through a powerful “Compare and Evaluate” engine that reconciles millions of records between heterogeneous sources in under a minute. For deeper analysis, Qyrus performs automated data quality checks on row counts, schema types, and custom business logic using sophisticated Lambda functions. This level of granularity ensures that your data quality validation in ETL remains airtight, even as your data volume explodes.
Qyrus also future-proofs your organization for the next generation of automation: Agentic AI. While disparate tools create data silos that blind AI agents, Qyrus provides the unified context these agents need to perform autonomous root-cause analysis and self-healing. By leveraging Nova AI to identify validation patterns automatically, your team can build test cases 70% faster than traditional ETL testing automation tools allow. The results are definitive: case studies show 60% faster testing cycles and 100% accuracy with zero oversight errors.
The 45-Day Detox: Purging Pipeline Pollution and Reclaiming Truth
Transforming a quality strategy requires a structured path rather than a blind leap. Most enterprises hesitate to move away from legacy ETL testing automation tools because the migration feels overwhelming. However, a phased transition minimizes risk while delivering immediate visibility into your pipeline health. Organizations adopting unified platforms see a significant financial turnaround, with total benefits often reaching more than 200% over a three-year period.
The first 30 days focus on discovery within a zero-configuration sandbox. You connect directly to your existing sources and process a staggering 10 million rows per minute to expose critical flaws. This phase replaces manual data quality validation in ETL with high-speed automated data quality checks that provide instant feedback on your data health. Your team focuses on validation results instead of wrestling with infrastructure or complex configurations.
Following discovery, a two-week Proof of Concept (POC) deepens your insights. During this sprint, you build an ETL data testing framework tailored to your unique business logic and complex transformations. You generate detailed differential reports to pinpoint every discrepancy for rapid remediation.
Finally, you scale these data quality testing tools across the entire enterprise. Seamless integration into your CI/CD pipelines ensures that every code commit or deployment triggers a rigorous validation. This automated approach reduces manual testing labor by 60%, allowing your engineers to focus on innovation rather than maintenance.
The Strategic Fork: Choosing Between Technical Debt and Data Integrity
The decision to modernize your quality stack is no longer just a technical choice; it defines your organization’s ability to compete in a data-first economy.
Continuing with a patchwork of disconnected ETL testing automation tools ensures that technical debt will eventually outpace your innovation. Leaders who embrace a unified approach fundamentally restructure their economic outlook.
This transition effectively cuts your annual testing costs by 51% by eliminating redundant licenses and infrastructure overhead. More importantly, it liberates your engineering talent from the drudgery of tool maintenance and the “Fragmentation Tax” that slows down every release.
By implementing an integrated ETL data testing framework, you ensure that data quality validation in ETL becomes a silent, automated safeguard rather than a constant bottleneck. Proactive automated data quality checks provide the unshakeable foundation of truth required for trustworthy AI and precision analytics.
The era of guessing is over.
You can now replace uncertainty with a definitive “TestOS” that protects your bottom line and empowers your team to move with absolute confidence.
Your journey toward data integrity starts with a single strategic pivot. Contact us today!
SAP releases updates at breakneck speed. Development teams are sprinting forward, leveraging AI-assisted coding to deploy features faster than ever. Yet, in conference rooms across the globe, SAP Quality Assurance (QA) leaders face a grim reality: their testing cycles are choking innovation. We see this friction constantly in the field—agility on the front-end, paralysis in the backend.
The gap between development speed and testing capability is not just a process issue; it is a financial liability. Modern enterprise resource planning (ERP) systems, particularly those driven by SAP Fiori and UI5, have introduced significant complexities into the Quality Assurance lifecycle. Fiori’s dynamic nature—characterized by frequent updates and the generation of dynamic control identifiers—systematically breaks traditional testing models.
When business processes evolve, the Fiori applications update to meet new requirements, but the corresponding test cases often lag behind. This misalignment creates a dangerous blind spot. We often see organizations attempting to validate modern, cloud-native SAP environments using methods designed for on-premise legacy systems. This disconnect impacts more than just functional correctness; it hampers the ability to execute critical SAP Fiori performance testing at scale. If your team cannot validate functional changes quickly, they certainly cannot spare the time to load test SAP Fiori applications under peak user conditions, leaving the system vulnerable to crashes during critical business periods.
To understand why SAP Fiori test automation strategies fail so frequently, we must examine the three distinct evolutionary phases of SAP testing. Most enterprises remain dangerously tethered to the first two, unable to break free from the gravity of legacy processes.
Wave 1: The Spreadsheet Quagmire and the High Cost of Human Error
For years, “testing” meant a room full of functional consultants and business users staring at spreadsheets. They manually executed detailed, step-by-step scripts and took screenshots to prove validation.
This approach wasn’t just slow; it was economically punishing. Manual testing suffers from a linear cost curve—every new feature adds linear effort. Industry analysis suggests that the annual cost for manual regression testing alone can exceed $201,600 per environment. When you scale that across a five-year horizon, organizations often burn over $1 million just to stay in the same place. Beyond the cost, the reliance on human observation inevitably leads to “inconsistency and human error,” where critical business scenarios slip through the cracks due to sheer fatigue.
Wave 2: The False Hope of Script-Based Automation
As the cost of manual testing became untenable, organizations scrambled toward the second wave: Traditional Automation. Teams adopted tools like Selenium or record-and-playback frameworks, hoping to swap human effort for digital execution.
It worked, until it didn’t.
While these tools solved the execution problem, they created a massive maintenance liability. Traditional web automation frameworks rely on static locators (like XPaths or CSS selectors). They assume the application structure is rigid. SAP Fiori, however, is dynamic by design. A simple update to the UI5 libraries can regenerate control IDs across the entire application.
Instead of testing new features, QA engineers spend 30% to 50% of their time just setting up environments and fixing broken locators. This isn’t automation; it is just automated maintenance.
Wave 3: The Era of ERP-Aware Intelligence
We have hit a ceiling with script-based approaches. The complexity of modern SAP Fiori test automation demands a third wave: Agentic AI.
This new paradigm moves beyond checking if a button exists on a page. It focuses on “ERP-Aware Intelligence”—tools that understand the business intent behind the process, the data structures of the ERP, and the context of the user journey. We are moving away from fragile scripts toward intelligent agents that can adapt to changes, understand business logic, and ensure process integrity without constant human intervention.
To achieve the economic viability modern enterprises need, automation must do more than click buttons. It must reduce maintenance effort by 60% to 80%. Without this shift, teams will remain trapped in a cycle of repairing yesterday’s tests instead of assuring tomorrow’s releases.
The Technical Trap: Why Standard Automation Crumbles Under Fiori
You cannot solve a dynamic problem with a static tool. This fundamental mismatch explains why so many SAP Fiori test automation initiatives stall within the first year. The architecture of SAP Fiori/UI5 is built for flexibility and responsiveness, but those very traits act as kryptonite for traditional, script-based testing frameworks.
The “Dynamic ID” Nightmare
If you have ever watched a Selenium script fail instantly after a fresh deployment, you have likely met the Dynamic ID problem.
Standard web automation tools function like a treasure map: “Go to X coordinate and dig.” They rely on static locators—specific identifiers in the code (like button_123)—to find and interact with elements.
SAP Fiori does not play by these rules. To optimize performance and rendering, the UI5 framework dynamically generates control IDs at runtime. A button labeled __xmlview1–orderTable in your test environment today might become __xmlview2–orderTable in production tomorrow.
Because the testing tool cannot find the exact ID it recorded, the test fails. The application works perfectly, but the report says otherwise. These “false negatives” force your QA engineers to stop testing and start debugging, eroding trust in the entire automation suite.
The Maintenance Death Spiral
This instability triggers a phenomenon known as the Maintenance Death Spiral. When locators break frequently, your team stops building new tests for new features. Instead, they spend their days patching old scripts just to keep the lights on.
Industry data indicates that teams using code-centric frameworks like Selenium often spend 50% to 70% of their automation effort on maintenance.
If you spend 70% of your time fixing yesterday’s work, you cannot support today’s velocity. This high rework cost destroys the ROI of automation. You aren’t accelerating release cycles; you are merely shifting the bottleneck from manual execution to technical debt management.
The “Documentation Drift”
While your engineers fight technical fires, a silent strategic failure occurs: Documentation Drift.
In a fast-moving SAP environment, business processes evolve rapidly. Developers update the code to meet new requirements, but the functional specifications—and the test cases based on them—often remain static.
This creates a dangerous gap. Your tests might pass because they validate an outdated version of the process, while the actual implementation has drifted away from the business intent. Without a mechanism to triangulate code, documentation, and tests, you risk deploying features that are technically functional but practically incorrect.
The Tooling Illusion: Why Current Solutions Fall Short
When organizations realize manual testing is unsustainable, they often turn to established automation paradigms, but each category trades one problem for another. Model-based solutions, while offering stability, suffer from a severe “creation bottleneck,” forcing functional teams to manually scan screens and build complex underlying models before a single test can run. On the other end of the spectrum, code-centric and low-code frameworks offer flexibility but remain fundamentally “blind” to the ERP architecture. Because these tools rely on standard web locators rather than understanding the business object, they shatter the moment SAP Fiori test automation environments generate dynamic IDs, forcing teams to simply trade manual execution for manual maintenance.
Native legacy tools built specifically for the ecosystem might feel like a safer bet, but they lack the modern, agentic capabilities required for today’s cloud cadence. These older platforms miss critical self-healing features and struggle to keep pace with evolving UI5 elements, making them ill-suited for agile SAP Fiori performance testing. Ultimately, no existing category—whether model-based, script-based, or native—fully bridges the gap between the technical implementation and the business intent. They leave organizations trapped in a cycle where they must choose between the high upfront cost of creation or the “death spiral” of ongoing maintenance, with no mechanism to align the testing reality with drifting documentation.
Code-to-Test: The Agentic Shift in SAP Fiori Test Automation
We built the Qyrus Fiori Test Specialist to answer a singular question: Why are humans still explaining SAP architecture to testing tools? The “Third Wave” of QA requires a platform that understands your ERP environment as intimately as your functional consultants do. We achieved this by inverting the standard workflow. We moved from “Record and Play” to “Upload and Generate.”
SAP Scribe: Reverse Engineering, Not Recording
The most expensive part of automation is the beginning. Qyrus eliminates the manual “creation tax” through a process we call Reverse Engineering. Instead of asking a business analyst to click through screens while a recorder runs, you simply upload the Fiori project folder containing your View and Controller files.
Proprietary algorit hms, which we call Qyrus SAP Scribe, ingest this source code alongside your functional requirements. The AI analyzes the application’s input fields, data flow, and mapping structures to automatically generate ready-to-run, end-to-end test cases. This agentic approach creates a massive leap in SAP Fiori test automation efficiency. It drastically reduces dependency on your business teams and eliminates the need to manually convert fragile recordings into executable scripts. You get immediate validation that your tests match the intended functionality without writing a single line of code.
The Golden Triangle: Triangulated Gap Analysis
Standard tools tell you if a test passed or failed. Qyrus tells you if your business process is intact.
We introduced a “Triangulated” Gap Analysis that compares three distinct sources of truth:
- The Code: The functionality actually implemented in the Fiori app.
- The Specs: The requirements defined in your functional documentation.
- The Tests: The coverage provided by your existing validation steps.
Dashboards visualize exactly where the reality of the code has drifted from the intent of the documentation. The system then provides specific recommendations: either update your documentation to match the new process or modify the Fiori application to align with the original requirements. This ensures your QA process drives business alignment, not just bug detection.
The Qyrus Healer: Agentic Self-Repair
Even with perfect generation, the “Dynamic ID” problem remains a threat during execution. This is where the Qyrus Healer takes over.
When a test fails because a control ID has shifted—a common occurrence in UI5 updates—the Healer does not just report an error. It pauses execution and scans the live application to identify the new, correct technical field name. It allows the user to “Update with Healed Code” instantly, repairing the script in real-time. This capability is the key to breaking the maintenance death spiral, ensuring that your automation assets remain resilient against the volatility of SaaS updates.
Beyond the Tool: The Unified Qyrus Platform
Optimizing a single interface is not enough. SAP Fiori exists within a complex ecosystem of APIs, mobile applications, and backend databases. A testing strategy that isolates Fiori from the rest of the enterprise architecture leaves you vulnerable to integration failures. Qyrus addresses this by unifying SAP Fiori performance testing, functional automation, and API validation into a single, cohesive workflow.
Unified Testing and Data Management
Qyrus extends coverage beyond the UI5 layer. The platform allows you to load test SAP Fiori workflows under peak traffic conditions while simultaneously validating the integrity of the backend APIs driving those screens. This holistic view ensures that your system does not just look right but performs right under pressure.
However, even the best scripts fail without valid data. Identifying or creating coherent data sets that maintain referential integrity across tables is often the “real bottleneck” in SAP testing. The Qyrus Fiori Test Specialist integrates directly with Qyrus DataChain to solve this challenge. DataChain automates the mining and provisioning of test data, ensuring your agentic tests have the fuel they need to run without manual intervention.
Agentic Orchestration: The SEER Framework
We are moving toward autonomous QA. The Qyrus platform operates on the SEER framework—Sense, Evaluate, Execute, Report.
- Sense: The system reads and interprets the application code and documentation.
- Evaluate: It identifies gaps between the technical implementation and business requirements.
- Execute: It generates and runs tests using self-healing locators.
- Report: It provides actionable intelligence on process conformance.
This framework shifts the role of the QA engineer from a script writer to a process architect.
Conclusion: From “Checking” to “Assuring”
The path to effective SAP Fiori test automation does not lie in faster scripting. It lies in smarter engineering.
For too long, teams have been stuck in the “checking” phase—validating if a button works or a field accepts text. The Qyrus Fiori Test Specialist allows you to move to true assurance. By utilizing Reverse Engineering to eliminate the creation bottleneck and the Qyrus Healer to survive the dynamic ID crisis, you can achieve the 60-80% reduction in maintenance effort that modern delivery cycles demand.
Ready to Transform Your SAP QA Strategy?
Stop letting maintenance costs eat your budget. It is time to shift your focus from reactive validation to proactive process conformance.
If you are ready to see how SAP Fiori test automation can actually work for your enterprise—delivering stable locators, autonomous repair, and deep ERP awareness—the Qyrus Fiori Test Specialist is the solution you have been waiting for. Don’t let brittle scripts or manual regressions slow down your S/4HANA migration. Eliminate the creation bottleneck and achieve the 60-80% reduction in maintenance effort that your team deserves.
Book a Demo for the Fiori Test Specialist Today!


![Featured_Image-LLM_evaluation[1]](https://www.qyrus.com/wp-content/uploads/2026/03/Featured_Image-LLM_evaluation1.webp)