


Welcome to the third installment of our series on Agentic Orchestration. In our previous post, we explored the ‘Eyes and Ears’ of the operation—the Sense stage, which detects every change across the development ecosystem. But what happens next? In this chapter, we’re diving into the ‘Brain’ of the SEER framework: the intelligent Evaluate stage. If you’re just joining us, we recommend starting with Part 1 to grasp the foundational concepts.
How Qyrus Evaluates Change and Optimizes Testing
In software development, change is the only constant. But every change, no matter how small, introduces risk. How can you be confident that a minor code tweak won’t trigger a major application failure?
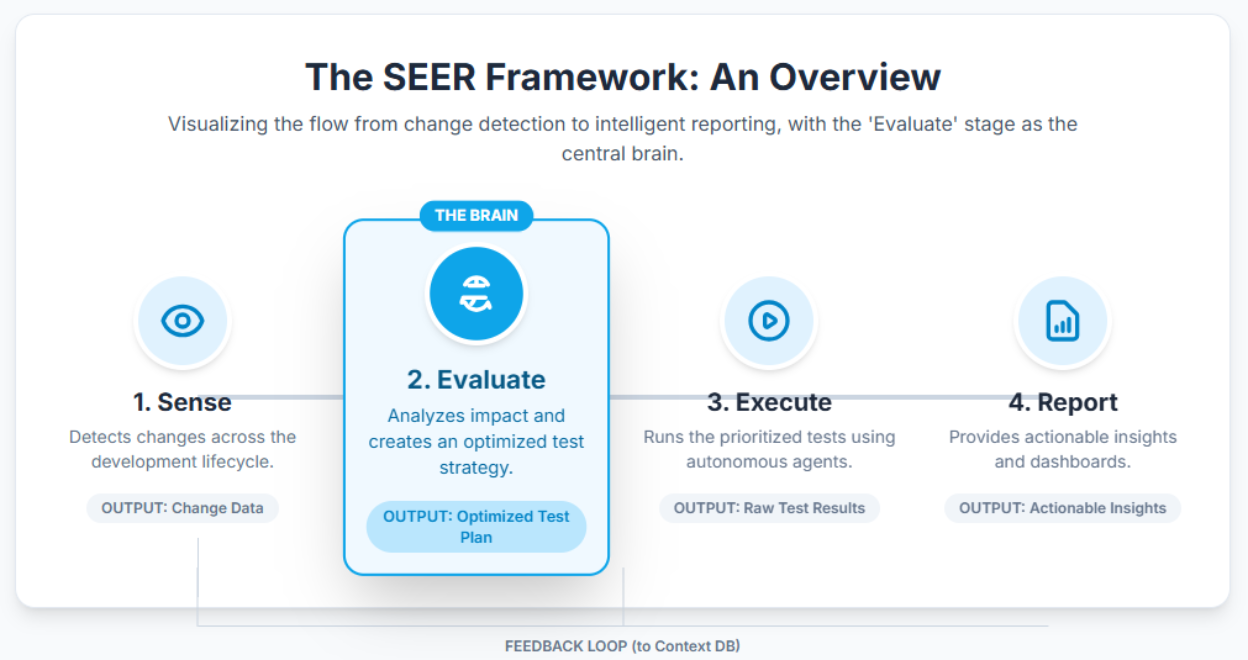
This is where the “Evaluate” stage of Qyrus’s SEER framework (Sense, Evaluate, Execute, Report) takes command. Building on the “Sense” stage which acts as the eyes and ears, the “Evaluate” stage is the strategic brain. It transforms raw data about changes into an intelligent, optimized testing strategy.
In this third installment, we’ll dissect how Qyrus performs its cognitive heavy lifting: analyzing the ripple effect of changes, generating the precise tests needed, and ensuring your testing efforts deliver maximum impact with minimum overhead.
Cognitive Crunch Time: From ‘What Changed?’ to ‘What Do We Do?’
The ‘Evaluate’ stage is where Qyrus flexes its AI muscle. Its primary goal is to answer the critical question that follows any detected change: “What is the smartest way to test this?” It achieves this through a sophisticated process of impact analysis, test creation, and strategy optimization.
Think of it as a lead detective arriving at a scene. The “Sense” stage has reported a change. Now, the “Evaluate” stage meticulously examines the evidence, traces potential connections, and formulates a precise plan of action. This ensures your testing is always laser-focused on the highest-risk areas, saving time and dramatically improving coverage.
Inside the Brain: How Evaluation Unfolds
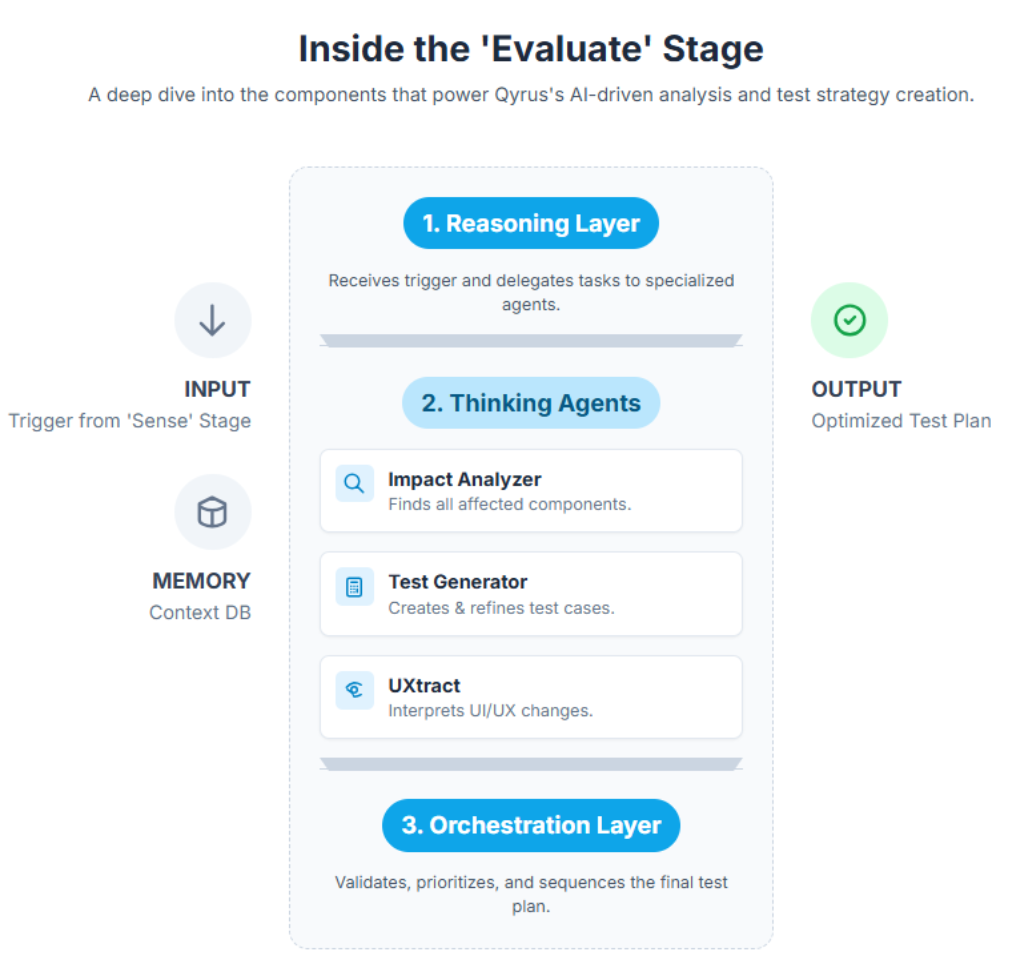
The evaluation process isn’t a single action but a coordinated symphony of specialized AI components. It begins with a trigger and flows through a logical sequence to produce a master test plan.
1. The Reasoning Layer: The Command Center
The Reasoning Layer is the control center of the ‘Evaluate’ stage, orchestrating logical decision-making upon receiving a trigger from the Watch Towers. It acts as the brain of the operation, directing the flow of information and coordinating the actions of the Thinking Agents.
Imagine a conductor leading an orchestra. The reasoning layer analyzes the incoming information about the changes, assesses their potential impact, and then delegates tasks to specialized “Thinking” agents. It determines which agent is best suited to analyze the change, generate relevant test cases, and optimize the testing strategy. This intelligent delegation of tasks ensures that the evaluation process is efficient, effective, and focused on the areas that matter most.
2. The Thinking Agents: A Squad of AI Specialists
These are the specialized AI-driven models, or Single Use Agents (SUAs), that perform specific tasks within the ‘Evaluate’ stage. They are experts in their respective domains, working together to analyze the impact of changes, generate relevant test cases, and optimize the testing strategy.
Think of them as specialized detectives, each with their own unique skills and expertise. Some are experts in analyzing code, others in understanding user flows, and yet others in generating test cases. This specialization ensures that every aspect of the change is thoroughly evaluated, and the most effective testing strategy is devised.
The thinking agents include:
- Impact Analyzer: This agent acts as the forensic expert. Using static analysis, dependency graphs, and historical data, it maps out the potential ripple effect of a code change. It answers the question: “If this line of code changes, which other modules, components, or APIs could be affected?”
- Test Generator: Leveraging Natural Language Processing (NLP), this agent functions as the strategist. It compares updated requirements and the impact analysis against existing tests. It then dynamically generates new, relevant test cases and refines existing ones to ensure complete coverage.
- UXtract: This agent is the visual design expert. It meticulously extracts and interprets UI/UX changes, mapping differences between design files (like Figma versions) to specific user flows and test steps. This guarantees that visual integrity and accessibility are never compromised.
3. The Context DB: The System’s Long-Term Memory
The Context DB serves as the memory bank of the ‘Evaluate’ stage, a central data store containing historical test results, system configurations, defect trends, and traceability data. The SUAs use the data in the Context DB as one of the inputs for their reasoning.
Imagine a detective’s case files, filled with past experiences, insights, and knowledge. The Context DB provides the Thinking Agents with valuable context and information to make informed decisions. This historical data helps them analyze the impact of changes more accurately, generate more relevant test cases, and optimize the testing strategy for maximum effectiveness.
4. The Orchestration Layer: The Conductor of the Evaluation Symphony
This layer’s objective is to coordinate and validate decisions from the Thinking Agents. Its function is to serve as an orchestrator or “meta-controller” that confirms which test sets should be executed and in which sequence, applying business rules and testing policies.
Imagine a conductor leading an orchestra, ensuring that each musician plays their part in harmony with the others. The Orchestration Layer takes the recommendations from the Thinking Agents and creates a cohesive testing strategy. It ensures that the tests are executed in the right order, with the right resources, and in line with the overall testing policies and business rules. This coordination and validation ensure that the testing process is efficient, effective, and aligned with the organization’s goals.
The Payoff: Intelligent, Optimized, and Comprehensive Testing
The ‘Evaluate’ stage provides several benefits that greatly improve the testing process:
- Intelligent Test Creation: By dynamically generating relevant test cases based on changes and requirements, the ‘Evaluate’ stage reduces the manual effort required to create and maintain tests. The Test Generator considers existing scenarios and suggests new ones, ensuring comprehensive test coverage. This AI test generator not only saves time but also ensures that your tests are always relevant and up to date.
- Optimized Test Execution: The stage prioritizes and sequences tests for maximum efficiency. This ensures that the most important tests are run first, allowing for faster feedback and quicker identification of critical defects. With test optimization, you can be confident that your testing efforts are focused on the areas that matter most.
- Comprehensive Impact Analysis: The Impact Analyzer identifies affected components, ensuring complete test coverage. This helps to focus testing efforts on the areas most likely to be impacted by a change, reducing the risk of overlooking critical issues. Impact analysis ensures that no stone is left unturned in your quest for quality software.
By combining intelligent test generation, optimized test execution, and comprehensive impact analysis, the ‘Evaluate’ stage empowers teams to achieve unparalleled efficiency and effectiveness in their AI-driven testing efforts. It’s like having a team of expert testers and strategists working tirelessly behind the scenes, ensuring that your testing process is always one step ahead. With Qyrus SEER, you can say goodbye to guesswork and embrace a data-driven approach to testing, where every decision is backed by intelligent insights and optimized for maximum impact.
Conclusion: Evaluate to Elevate
The ‘Evaluate’ stage is the strategic heart of the Qyrus SEER framework, transforming raw change data into an actionable intelligence blueprint. It’s how we move from reactive testing to a predictive, optimized, and truly AI-driven strategy.
But a brilliant strategy is only as good as its execution. In the next part of our series, we’ll explore the ‘Execute’ stage, where this carefully crafted plan is put into action. Stay tuned to see how Qyrus orchestrates a fleet of agents to seamlessly run tests, gather results, and bring you one step closer to fully autonomous testing.
Ready to put our AI brain to the test? Schedule a demo with Qyrus today!
Other Blog Posts in the Series
The Agentic Orchestration Series, Part 5: Test Insights – The Voice of the Operation


