

What Is Agentic QA And How AI Agents Are Redefining Software Testing
 Varun RS
Varun RS

Software delivery is breaking. It isn’t a loud failure or a single high-profile incident; rather, it’s a quiet divergence between development speed and testing capacity. It happened gradually, then all at once: AI coding tools got good enough that developers started shipping code at a pace testing teams were never built to match.
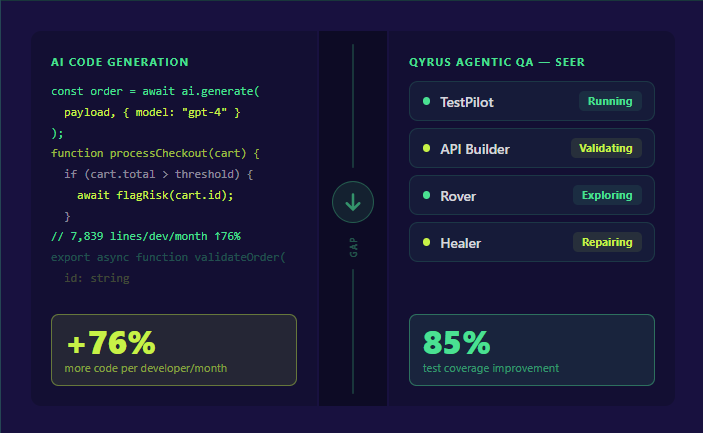
By 2025, 90% of engineering teams were using AI coding assistants to accelerate delivery. Industry experts confirmed at Transform 2025 that over 40% of all code written that year was AI-generated. Individual developer output surged — one analysis found the average developer now submits 7,839 lines of code per month1, up from 4,450 just two years prior.
The downstream consequence? A study of 273 QA decision-makers2, published in January 2026, found that 60% of organizations had already experienced quality failures because development moved faster than testing could validate. Critically, 92% of those teams still tested manually, despite 87% having some automation in place. Existing automation was no longer keeping up.
Forrester captured the structural problem precisely: the industry has plateaued at roughly 25% automated test coverage. Traditional automation has been plateaued. The same AI revolution that widened the velocity gap is now the only force capable of closing it. That force is agentic QA.
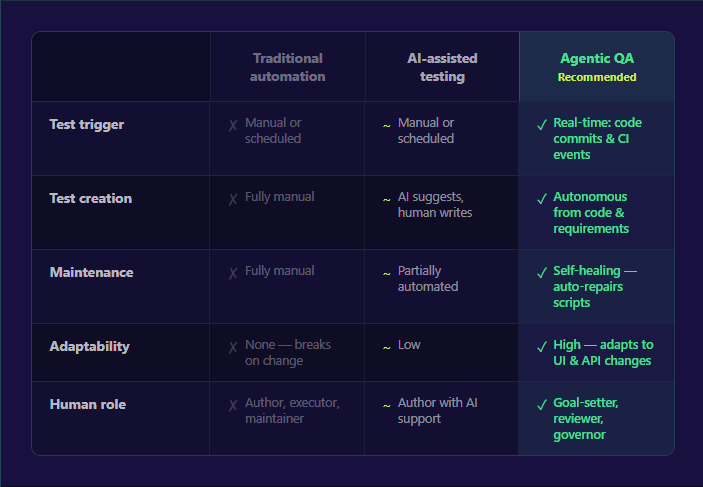
One question comes up immediately: does this replace QA engineers? The data says no. The Stack Overflow 2025 Developer Survey found 70% of developers do not see AI as a threat to their jobs. What changes is the nature of the work. Agents handle the repetitive 80% of work, including regression suites, smoke tests, selector maintenance, and visual comparison. Human testers focus on the strategic 20%: defining quality objectives, exploratory testing, edge case discovery, and ensuring AI-generated results align with business intent. Agentic QA does not eliminate the QA function. It elevates it.
How AI Agents for QA Testing Actually Work
Understanding agentic QA in principle is one thing. Understanding what AI agents for software testing actually do inside a real development pipeline is where the concept becomes actionable.
A mature agentic QA system operates across five interconnected capabilities. These are not features bolted onto an existing automation tool. They are the architectural building blocks that make autonomous, self-improving testing possible.

1. Autonomous Test Generation
When a developer merges a pull request, an agentic system does not wait for a human to decide which tests to write or run. The system analyzes code changes, identifies coverage gaps, and automatically generates test cases for functional scenarios and regression paths that manual processes often overlook. Teams adopting this capability report up to an 80% reduction in test creation effort, freeing engineers to focus on higher-value validation work.
2. Self-Healing Tests
Brittle scripts are the single largest hidden cost in traditional automation. Forrester research notes that over 60% of QA leaders identify automation maintenance as a key bottleneck in DevOps success. When a UI element shifts — a button ID changes, a form field moves, an API endpoint is renamed — traditional scripts fail silently or noisily, and a human has to diagnose and repair them. Self-healing agents detect the change, identify the correct new locator using DOM structure, visual matching, or semantic analysis, and update the test automatically. One global retailer deploying this approach achieved a 95% reduction in script maintenance while doubling the speed of regression cycles.
3. Risk-Based Test Selection
Running every test on every commit is unsustainable at scale. Google learned this building one of the largest CI/CD infrastructures in the world, executing over 150 million test cases daily required ML-driven test selection to identify the smallest effective test set, reducing computational waste by over 30% while maintaining a 99.9% confidence level. Agentic QA brings this capability to any team. Agents analyze what changed in a commit, assess which components are affected using dependency graphs, and run only the tests with genuine relevance to that change. There are reports that AI-powered impact analysis reduces testing timelines by up to 85% while maintaining complete risk coverage.
4. Real-Time Adaptive Testing
Traditional automation runs on schedules. Agentic QA reacts to events — a code commit, a Jira ticket update, a Figma design change, a failed deployment. This shift from batch-mode to real-time adaptive testing is what allows quality assurance to finally match the pace of modern development cycles. Feedback that once took hours arrives in minutes, enabling development teams to catch and fix defects before they compound.
5. Multi-Agent Orchestration
No single agent handles everything. A mature agentic QA system deploys specialized agents in parallel: one focused on UI interactions, another validating API responses, a third exploring untested pathways autonomously, and a fourth consolidating results into prioritized reports. This coordinated squad model, with a central orchestration layer routing work between agents. is what enables comprehensive test coverage across web, mobile, API, and backend layers simultaneously, rather than sequentially.
🔄 In Practice: A developer merges a feature update to a checkout flow. The agentic system detects the commit in real time, evaluates which user journeys and API endpoints are affected, generates new test cases for the updated flow, dispatches UI and API agents to execute them in parallel across multiple browsers and devices, self-heals any scripts broken by the UI change, and delivers a risk-prioritized report, all before the developer’s next meeting. That is not a future state. It is what production deployments of agentic QA systems are delivering today.
The Business Case — What the Numbers Say
Agentic QA is not a research project. Organizations deploying it are generating measurable, reportable returns — and the numbers are significant enough to reframe how executives think about the cost of quality engineering.
Start with the cost of inaction. Poor software quality costs the US economy an estimated $2.41 trillion annually, according to research from CISQ and Carnegie Mellon’s Software Engineering Institute. That figure encompasses failed projects, legacy system failures, cybersecurity incidents, and operational disruptions. Meanwhile, software testing already consumes 15–25% of a typical project budget — among the first line items cut when AI is assumed to close the gap automatically. It does not close the gap automatically. Agentic QA does.
On the delivery side, the returns compound across multiple dimensions simultaneously:
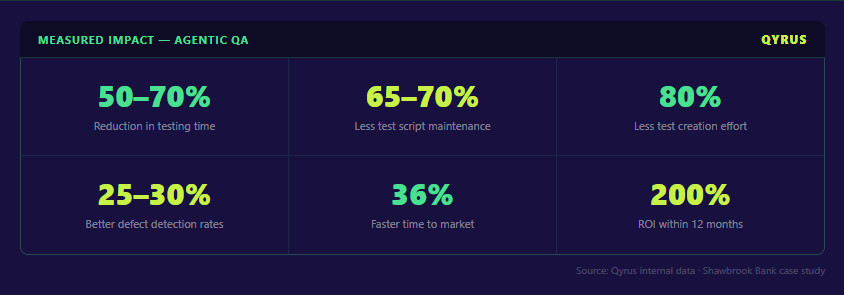
- Speed: Teams adopting agentic orchestration achieve a 50–70% reduction in overall testing time. Regression cycles that once occupied entire sprint days compress into hours. One ERP enterprise reduced regression testing from over 25 hours to under 8 hours per cycle after deploying agentic QA — with more issues caught pre-production and more predictable releases as a direct result.
- Maintenance: The largest hidden cost in traditional automation is not test creation — it is upkeep. Agentic QA’s self-healing capability delivers a 65–70% decrease in the engineering effort required to maintain test scripts. For a mid-size QA team spending 50% of sprint capacity on broken test maintenance, that recovery represents significant bandwidth redirected toward coverage expansion and exploratory testing.
- Creation velocity: With agents generating test cases from requirements, user stories, and code changes autonomously, teams see an 80% reduction in test creation effort. Tests that previously took days to author and validate are produced and ready for review in minutes.
- Quality outcomes: Faster testing and less maintenance would mean nothing if defect detection suffered. It does not. Organizations adopting agentic QA report a 25–30% improvement in defect detection rates, with AI-generated test cases achieving up to 85% improvement in test coverage — catching more critical bugs before they reach customers.
- Business impact: These improvements compound into outcomes that matter at the board level: an 80% reduction in defect leakage, a 36% faster time to market, and a ~40% improvement in project turnaround time. A Shawbrook Bank deployment of Qyrus demonstrated 200% ROI within 12 months — a figure that shifts the conversation from “what does this cost?” to “what does waiting cost?”
Broader market data reinforces the direction. Companies using AI agents across business functions report 55% higher operational efficiency and average cost reductions of 35%. In QA specifically, organizations implementing AI-powered testing solutions report a 40% reduction in overall testing costs while achieving productivity gains of up to 30%.
How Qyrus Approaches Agentic QA — The SEER Framework
Most platforms describe agentic QA as a capability. Qyrus built a purpose-designed architecture around it.
In Q4 2025, Forrester named Qyrus a Leader in its inaugural Autonomous Testing Platforms Wave — the report that replaced the former Continuous Automation Testing Platforms category and evaluated 15 vendors on their ability to deliver genuinely autonomous, AI-driven quality assurance. Qyrus received the highest possible score of 5.0 in critical criteria including Roadmap, Testing AI Across Different Dimensions, and Testing Agentic Tool Calling. The report specifically cited the SEER framework and “excellent agentic tool calling” as the basis for an above-par score in autonomous testing. For enterprises asking whether agentic QA is production-ready, that evaluation offers a clear answer.
The SEER framework — Sense, Evaluate, Execute, Report — is the operational engine behind Qyrus’s agentic QA approach. It is a continuous, closed-loop cycle designed to align the pace of quality assurance with the pace of modern software development.
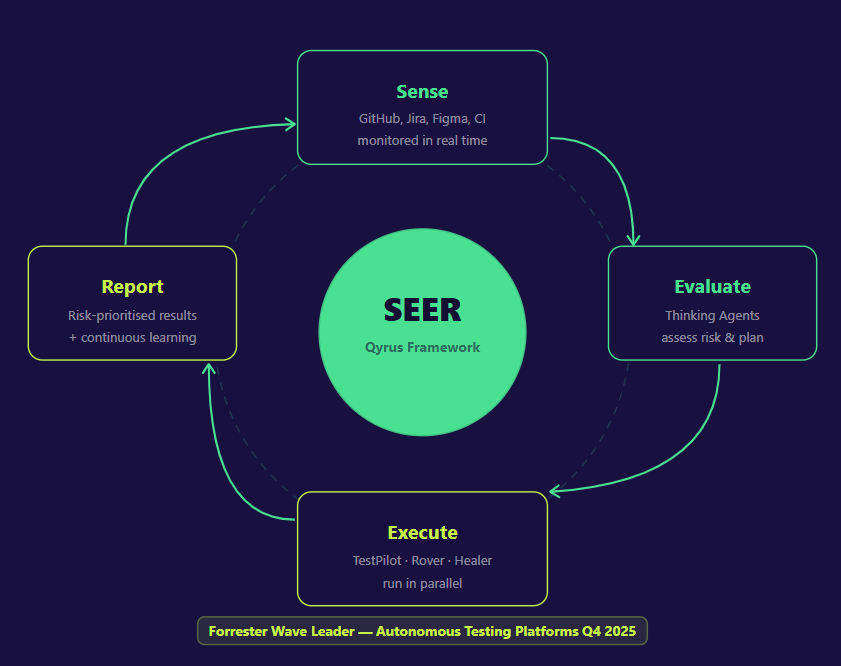
Sense
The cycle begins with awareness. Qyrus Watch Towers monitor code repositories like GitHub for commits and pull request merges, project management tools like Jira and Azure DevOps for story and requirement changes, design platforms like Figma for UI and UX updates, and CI pipeline events in real time. Testing does not start on a schedule. It starts the moment a change is detected.
Evaluate
Once a change is detected, a Reasoning Layer assesses its potential impact and deploys specialized Thinking Agents to formulate a response. The Impact Analyzer traces the ripple effect of a code change across modules, components, and APIs using dependency graphs. TestGenerator+ uses natural language processing to dynamically generate new test cases based on what changed and what coverage already exists — constantly expanding the test surface without human authoring. UXtract interprets design changes from Figma and maps them to the relevant test steps and user flows. The output of this stage is a precise, risk-prioritized testing plan, not a blanket instruction to run everything.
Execute
The plan is handed to an autonomous execution squad. TestPilot handles UI and functional testing across web and mobile platforms, simulating real user interactions across a browser and device farm. The API Builder agent validates backend services and complex integration points, with the ability to virtualize APIs on demand. Rover explores the application autonomously, surfacing untested pathways and hidden defects that scripted tests would never reach. Healer — built on US Patent 11,205,041 B2 — monitors execution in real time and automatically repairs any test script broken by a legitimate UI or structural change. These agents operate in parallel, not in sequence, compressing execution time without sacrificing coverage.
For enterprise teams running SAP testing, this same squad extends into ERP-aware validation — analyzing transport requests, mapping business process impact, and executing regression tests autonomously across S/4HANA landscapes.
Report
Raw results become actionable intelligence. AnalytiQ aggregates logs and metrics from the entire execution squad. Eval, a sophisticated AI analyst, evaluates test outputs for deep contextual analysis that goes far beyond a binary pass/fail. The final output — a risk-prioritized defect list, a coverage summary, and an instant notification to the right stakeholders via Slack, email, or Jira — arrives in minutes, not hours. Every outcome is fed back into the Context DB, making the Thinking Agents smarter and more predictive with every cycle.
This is what distinguishes Qyrus from platforms that bolt agentic labels onto existing automation tools. SEER is not a feature. It is a continuously learning system — and the results it delivers compound over time.
Getting Started with Agentic QA — A Practical Roadmap
Most organizations stall between interest and implementation. The World Quality Report 2025, drawing on responses from over 2,000 executives across 22 countries, found that 89% of organizations are piloting or deploying AI-augmented QA workflows — but only 15% have achieved enterprise-wide implementation. That 74-point gap is not a technology problem. It is an execution problem.
Gartner adds a sharper warning: over 40% of agentic AI projects will be cancelled by end of 2027 due to escalating costs, unclear business value, and inadequate risk controls. The organizations that avoid this fate share one trait — they defined measurable goals and governance structures before they expanded scope. The ones that fail treat agentic QA as a plug-in rather than a system change.
Four steps separate the teams getting results from the ones stuck in perpetual pilots.
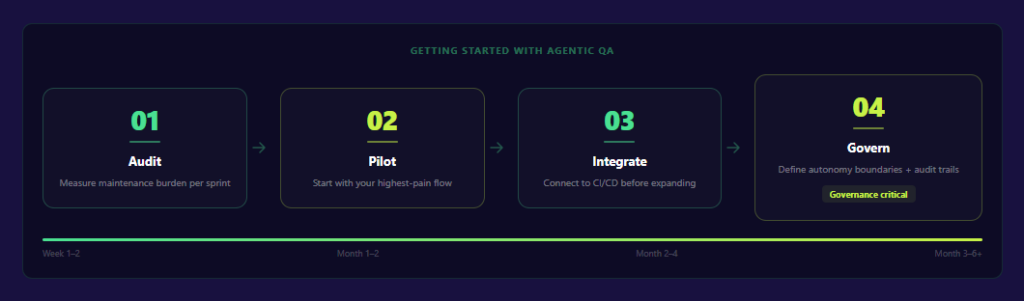
Step 1: Quantify Maintenance Latency Prior to Implementation
Before evaluating platforms or running proofs of concept, measure where your team’s time actually goes. How many hours per sprint does your QA function spend fixing broken tests that failed because of a UI change — not because of an actual product defect? Industry benchmarks suggest this figure consumes 20–30% of a QA team’s working week in traditional automation environments. That number is your baseline. It is also your first ROI target. If you cannot measure it before deployment, you cannot prove improvement after.
Step 2: Start With Your Highest-Pain Flow, Not Your Entire Pipeline
The instinct to modernize everything at once is where projects collapse under their own weight. Pick one regression suite or smoke test suite — ideally one that breaks frequently, consumes disproportionate maintenance time, or sits on a critical user journey. Run your agentic QA pilot there. Let it prove value in a constrained, measurable environment before expanding. Teams that start small and iterate build the internal confidence — and the data — needed to justify broader rollout. Those that start broad rarely finish.
Step 3: Integrate Into Your Existing CI/CD Before Adding New Capabilities
Agentic QA delivers its full value when it operates as a continuous, event-driven layer inside your development pipeline — not as a separate testing tool you run on demand. Before unlocking advanced capabilities like exploratory agents or multi-surface orchestration, ensure your agentic platform is connected to your existing infrastructure: GitHub or Bitbucket for version control triggers, Jenkins, Azure DevOps, or TeamCity for CI pipeline integration, and Jira or Azure DevOps for defect tracking and traceability. Integration before innovation is the sequencing that separates production deployments from permanent pilots.
Step 4: Govern From Day One
Autonomy without governance is where agentic AI projects generate the most risk — and the most expensive failures. Before agents operate independently in your pipeline, define three things explicitly: what the agent is authorized to act on without human review, what requires human approval before proceeding, and how every agent action is logged for audit. UC Berkeley’s CLTC published the first Agentic AI Risk Management Profile in February 2026, recommending proportional oversight calibrated to the autonomy level of each deployed agent. That framework is a practical starting point. The teams succeeding with agentic QA in 2026 are not those that maximized autonomy fastest — they are those that built trust incrementally, expanded scope based on demonstrated accuracy, and kept human judgment at the decision points that carry the most business risk.
Agentic QA is not a one-time implementation. It is a system that gets smarter with every cycle — but only if the governance structures exist to let it operate reliably at scale.
The Shift Has Already Happened
Agentic QA is not approaching. It is here. And the organizations treating it as a future consideration are already falling behind the ones running it in production.
Forrester’s Q4 2025 Autonomous Testing Platforms Wave was not a prediction. It was a verdict: autonomous, AI-driven quality assurance has crossed from experimental to essential infrastructure. The teams winning today are not those with the largest QA headcounts or the most elaborate script libraries. They are the ones that stopped asking “how do we test faster?” and started asking “how do we set better quality goals and let intelligent agents pursue them?”
That is the real shift agentic QA delivers. From writing scripts to defining outcomes. From managing test maintenance to governing autonomous systems. From QA as a bottleneck to QA as a continuous, self-improving competitive advantage embedded directly in the development cycle.
The velocity gap is real. The tools to close it exist. The only remaining question is whether your organization moves now, while the gap between early adopters and the rest of the market is still recoverable, or later, when it is not.

 June 19, 2026
June 19, 2026  20 min
20 min





